循环神经网络(RNN)是深度神经网络最重要的的形式之一,其被广泛运用于时序形数据的处理上、例如文字、音频、视频等等;而RNN在训练的过程中同样也会发生梯度不稳定的情况,同时还面临着新的数据不断加入循环而旧的数据不断被冲淡的情况,导致一个句子中开始的部分在最终结果的影响程度中较低,于是LSTM模型就诞生并用于改善这种情况
一、循环神经网络(Recurrent Neural Networks)
人在阅读文章、观看视频时,理解当前看到的东西,不会仅仅依靠当前的内容就作出理解,还要对上文进行综合理解,比如翻译The NBA player Kevin Love,当翻译Love时,应当翻译为乐福而不是喜欢,这是因为前面提到了NBA、player这些词。所以当使用深度神经网络进行翻译的时候就需要网络拥有对前文的记忆,这就是RNN出现的原因;
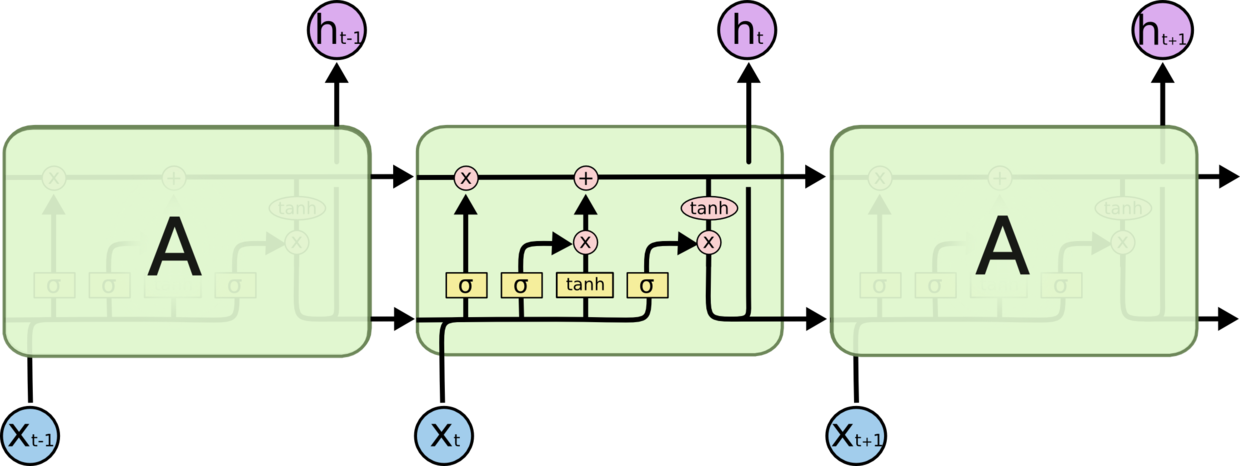
这是RNN的结构
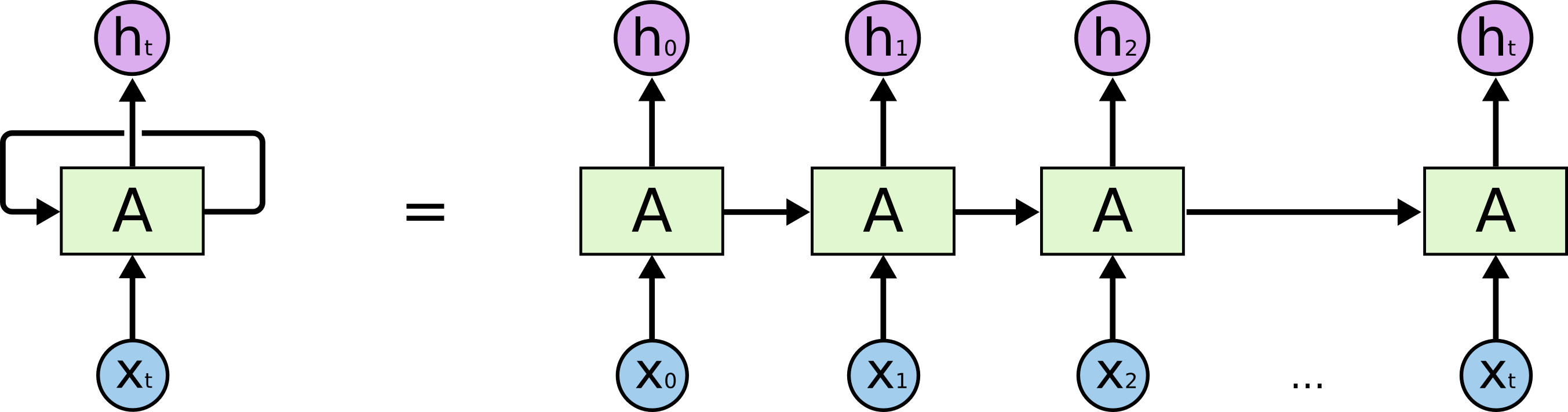
我们可以看到RNN是同一个单元的重复循环出现,每一次单元计算后都会产生一个记忆,传入下一个单元的计算,每一个单元都会接收当前的输入,并且考虑前面的记忆,作出当前的输出;
二、长短时记忆LSTM
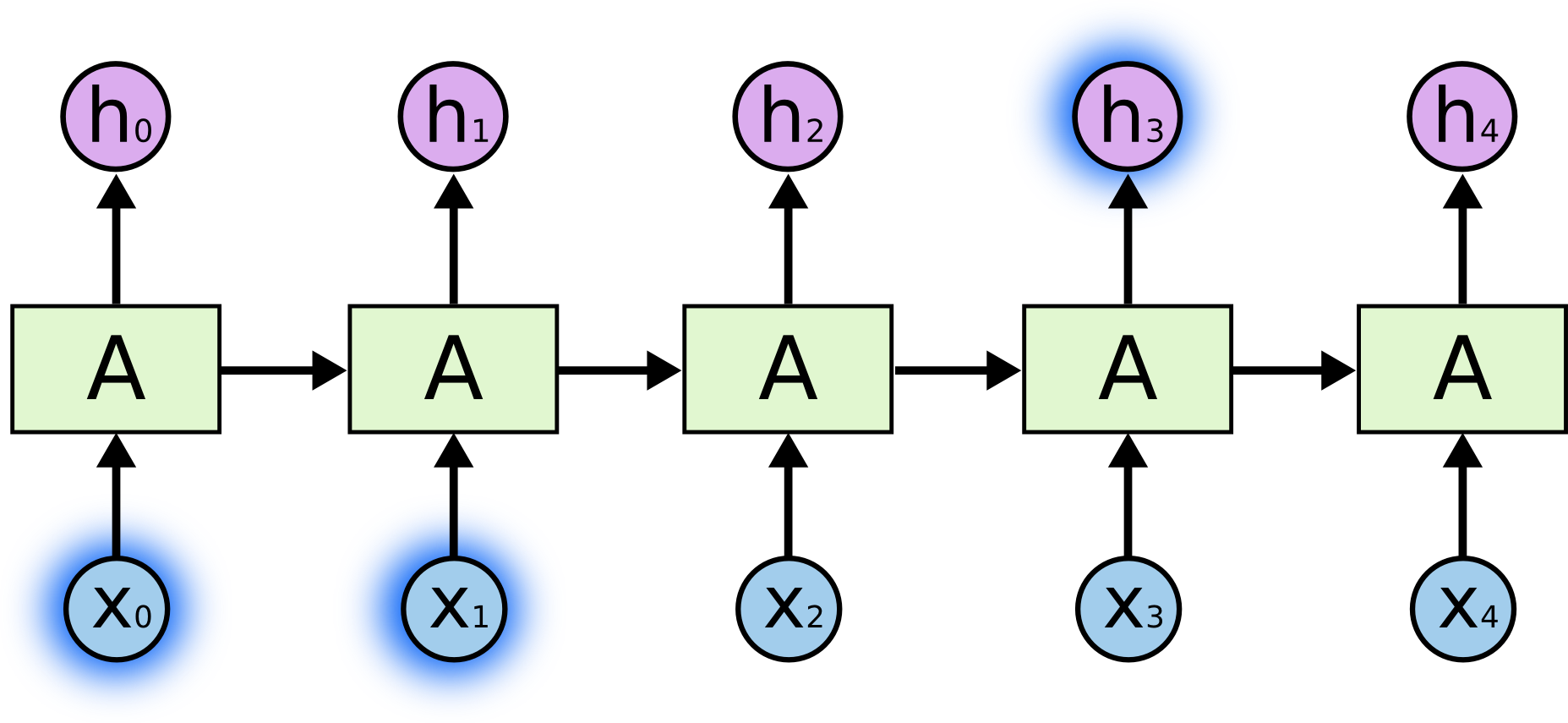
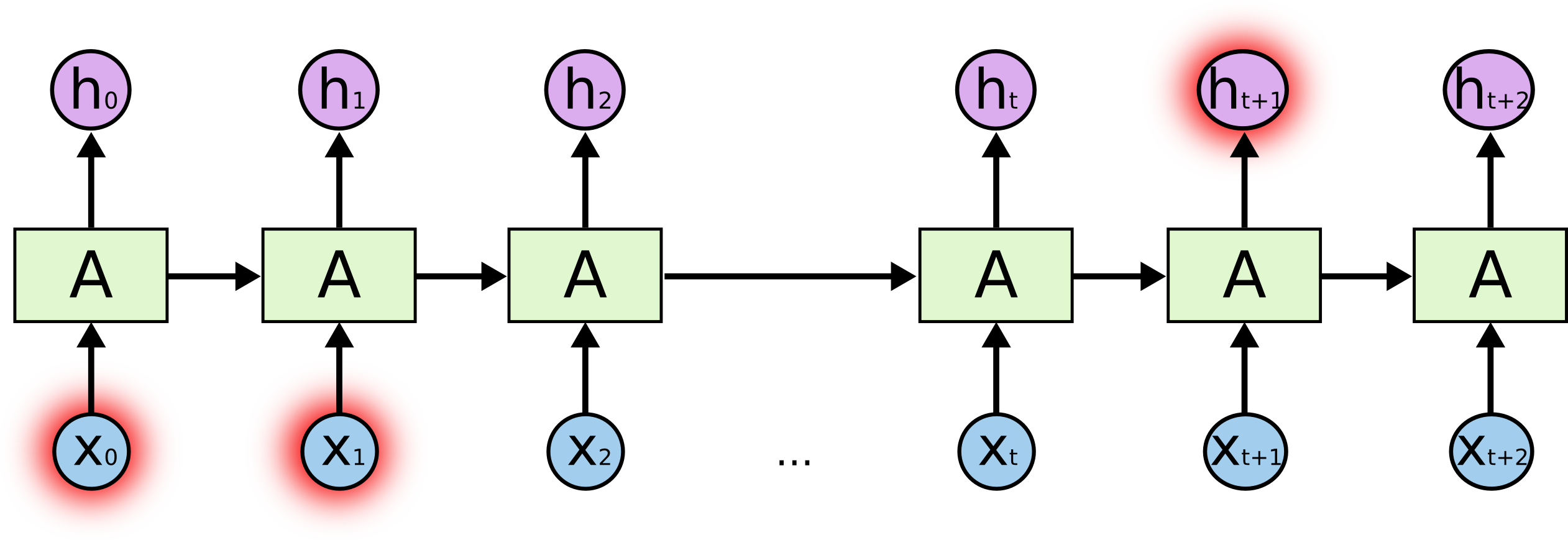
前面说到了普通的RNN单元会有Long-Term Dependencies的问题,就是每部所产生的记忆,可能只会对较近的几个输出产生影响,而随着网络加深,记忆将会消退,例如翻译“The NBA …(此处省略10000字)…Kevin Love”时,如果用普通的的RNN,那么Kevin Love依然有可能会被翻译为凯文喜欢,就如下图:
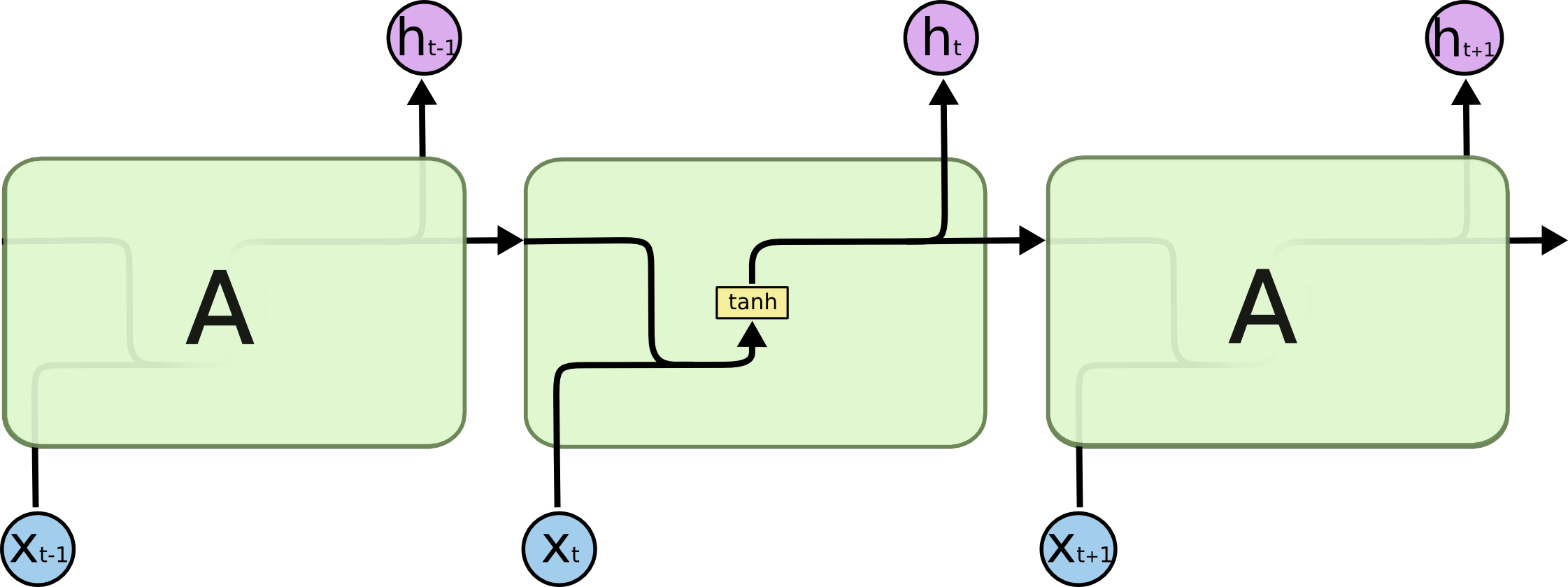
这时候就要请出我们今天的主角LSTM了,传统的RNN之所以不能够拥有很好的长时记忆是因为每个单元都是经过简单的线性变换加上tanh激活函数,如下图:
而LSTM则要复杂很多:
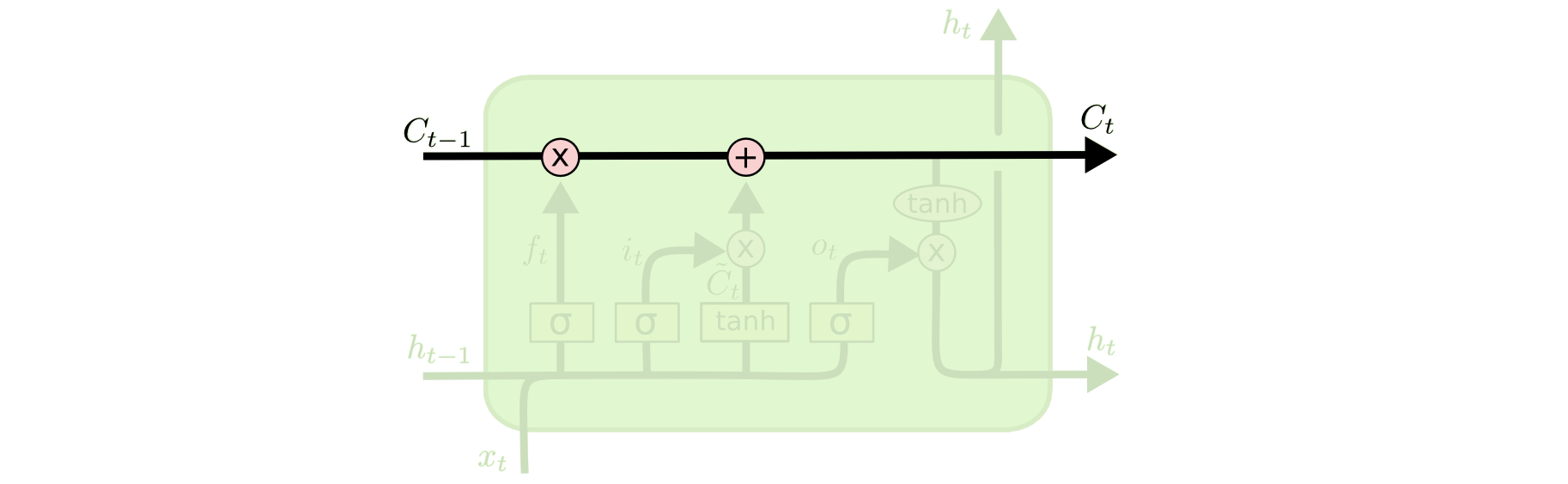
LSTM的记忆干流就是Ct,上一个单元的输入作用于它,并且与它一起形成这个单元的输出:
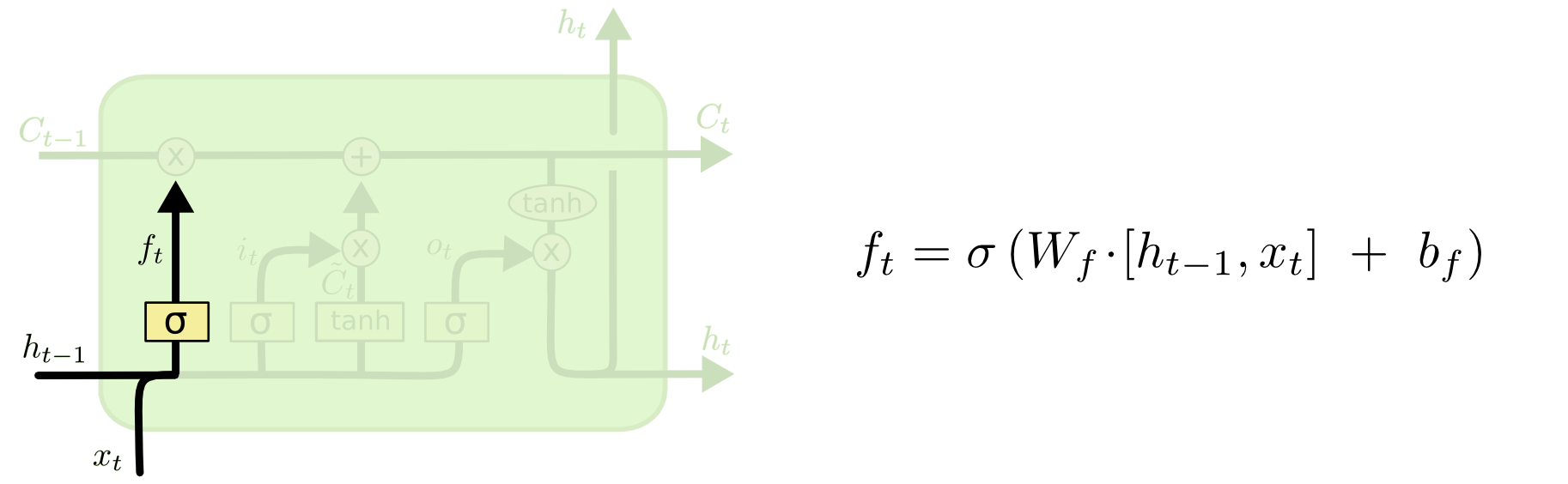
LSTM则包含了一个叫遗忘门的单元,用来判断上一单元传过来的记忆中哪些是可以忘记的,而哪些比较重要,需要记下
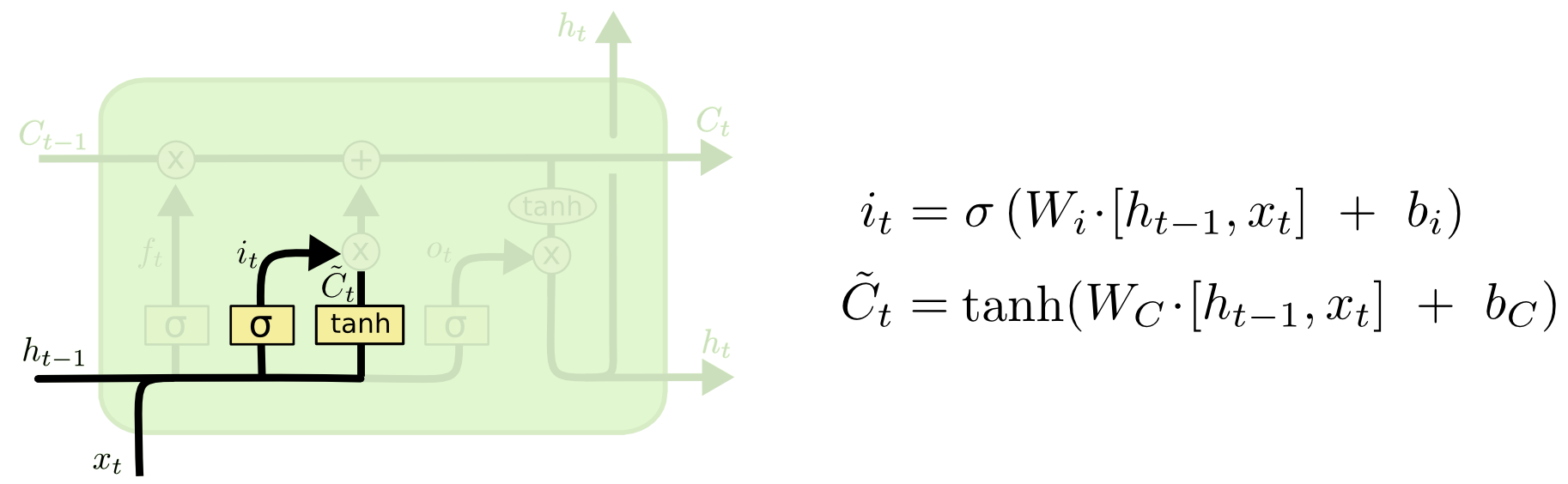
对本单元的输入信息进行提取
调整当前的记忆
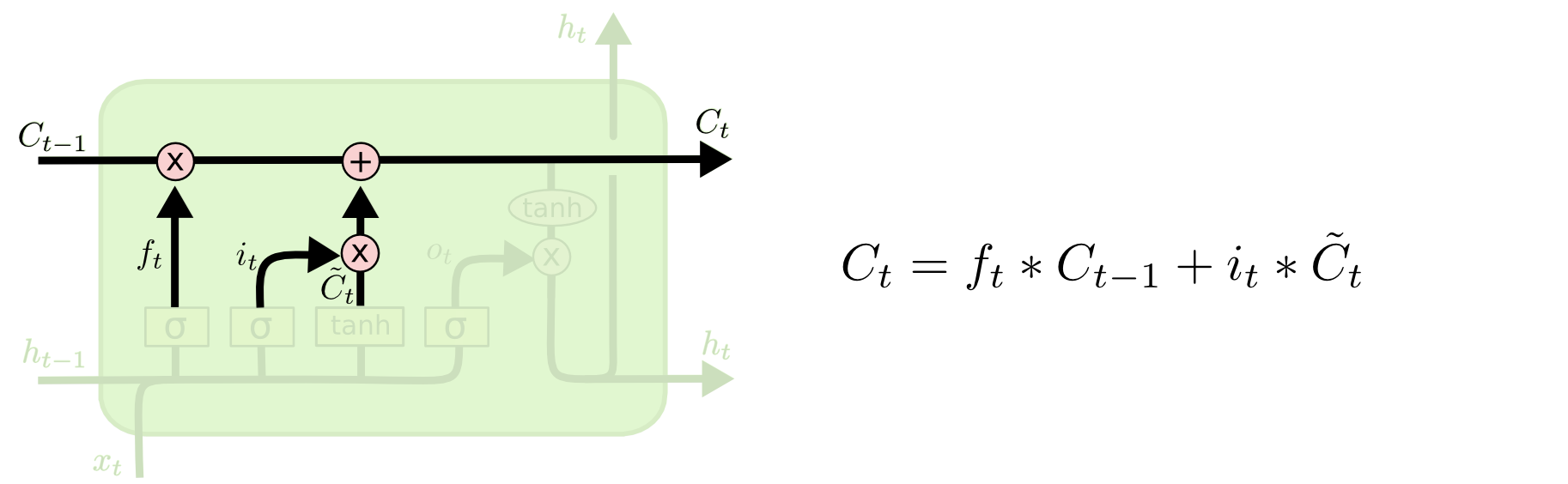
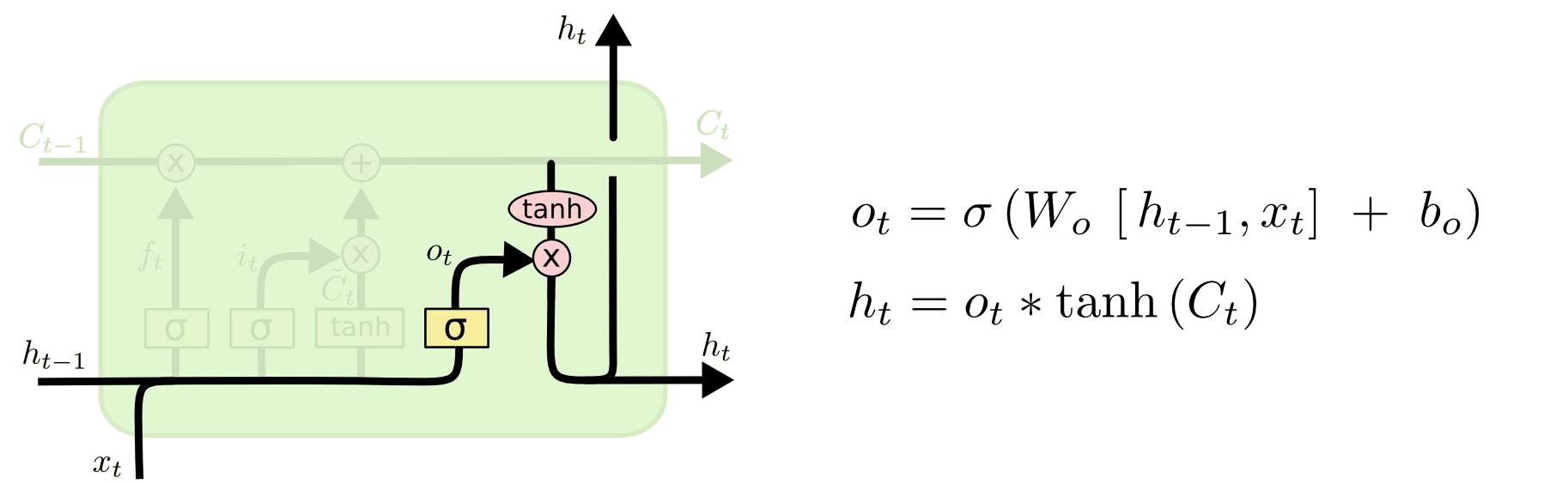
完成本单元的输出
三、LSTM变体——GRU
LSTM还拥有许多的变体,其中最常用的就是GRU,它是LSTM的一种简化,将C与h合二为一,拥有更好的效率,在某些任务上也有更好的效果
