前段时间一个任务需要获得日本所有主要城市的经纬度坐标,手头没有现成的数据,只能写一个简单的爬虫来爬取某旅游公司的页面来获得我要的经纬度数据。。采用一个方便简单的爬虫框架Request与BeautifulSoup,由于项目时间很赶,只是一个很简单的脚本,并不考虑动态页面,也没有与数据库进行交互,这部分的笔记以后再补,我会就着这次的代码简单介绍它们的使用方法
一、Requests与BeautifulSoup简介
Requests
Requests 是一个为人们制作的一个Python库,用于优雅且简单的HTTP
BeautifulSoup
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
Requests 与 BeautifulSoup一个负责请求页面,获得页面,一个负责解析页面内容,取出需要的数据
官方文档
二、安装Request与Beautiful
如果已经安装pip,那么安装就很简单
1 | $ pip insatall requests |
三、代码解析
完整的代码在这里
首先需要找到一个合适的网页并分析它的网页结构,我找到的一个网站结构是这样的:

打开开发者工具,可以发现网页的分页的链接是从index~index44
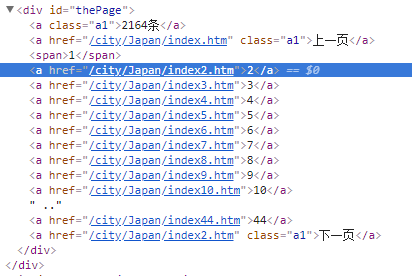
所以可以先将要爬取的网页以模版的形式装入
1 | #抓取的网页地址模版,所有分页的目录 |
对于每一页中的所有城市的电子地图,我们通过开发者工具可以发现它的结构是这样的:
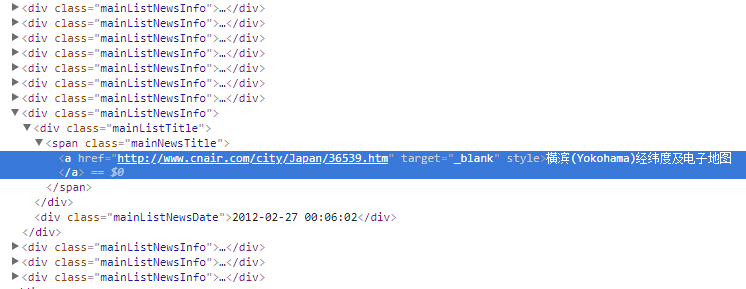
所以请求相应的页面后,我们需要找到存着相应子页面链接标签,发现他们位于class=‘mainListTitle’的<span>标签下的<a>标签下,所以可以使用BeautifulSoup进行提取
1 | for item in lists: |
访问相应的子页面,观察页面的结构

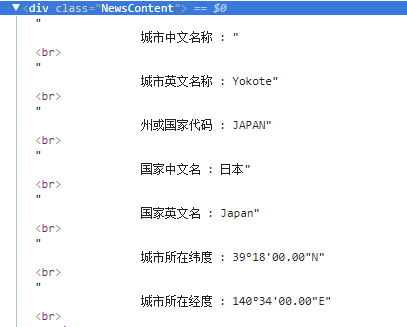
发现地名、经纬度等信息被放在了同一个class=’NewsContent’的<div>标签下,在同一个字符串中。所以我们需要从中提取出字符串,并以<br>作为分隔符,提取出他们。
1 | for u in urls: |
单位转换并保存到python的字典中,并最后保存到json文件中。这里有个小trick,爬取每个子页面后,可以让程序休眠1秒,爬取一个大页面后,可以停止10秒。这样做的目的是防止过于频繁的访问,导致服务器的拒绝访问。
1 | #存下刚刚抓取的信息 |