过拟合(overfit)是深度学习乃至机器学习过程中的又一大问题,通常的解决方法为L2正则化、Dropout正则化等等
一、L2正则化
L2正则化就是在原来的损失函数上,再加上一项参数的二范式
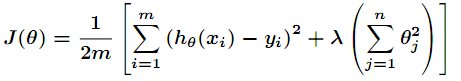
第二项又称作弗罗贝尼乌斯范数(Frobenius norm)的平方
将新的损失函数对参数求梯度得
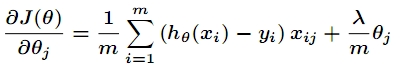
使用梯度下降更新参数
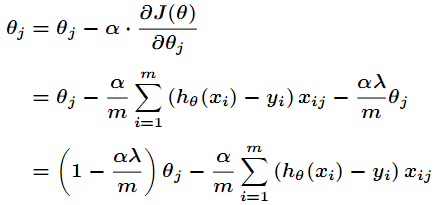
其中α、λ是两个超参数,α是学习率,而λ负责调节L2正则化过程
- λ=0时,表示不使用正则化
- λ越大,在训练过程中则会压制参数的变大,使参数尽量变小
二、L2正则化为什么有效
通俗的解释,产生过拟合问题的根本原因是模型试图记住的参数太多,导致其举一反三的能力减弱,而通过L2正则化,导致很多的参数会变得很小,对模型的影响力降低,相当于降低了模型的复杂程度,提高了泛化能力。
还有一种比较通俗的解释,来自Andrew Ng
我们的所常用的激活函数sigmoid、tanh是长这样的
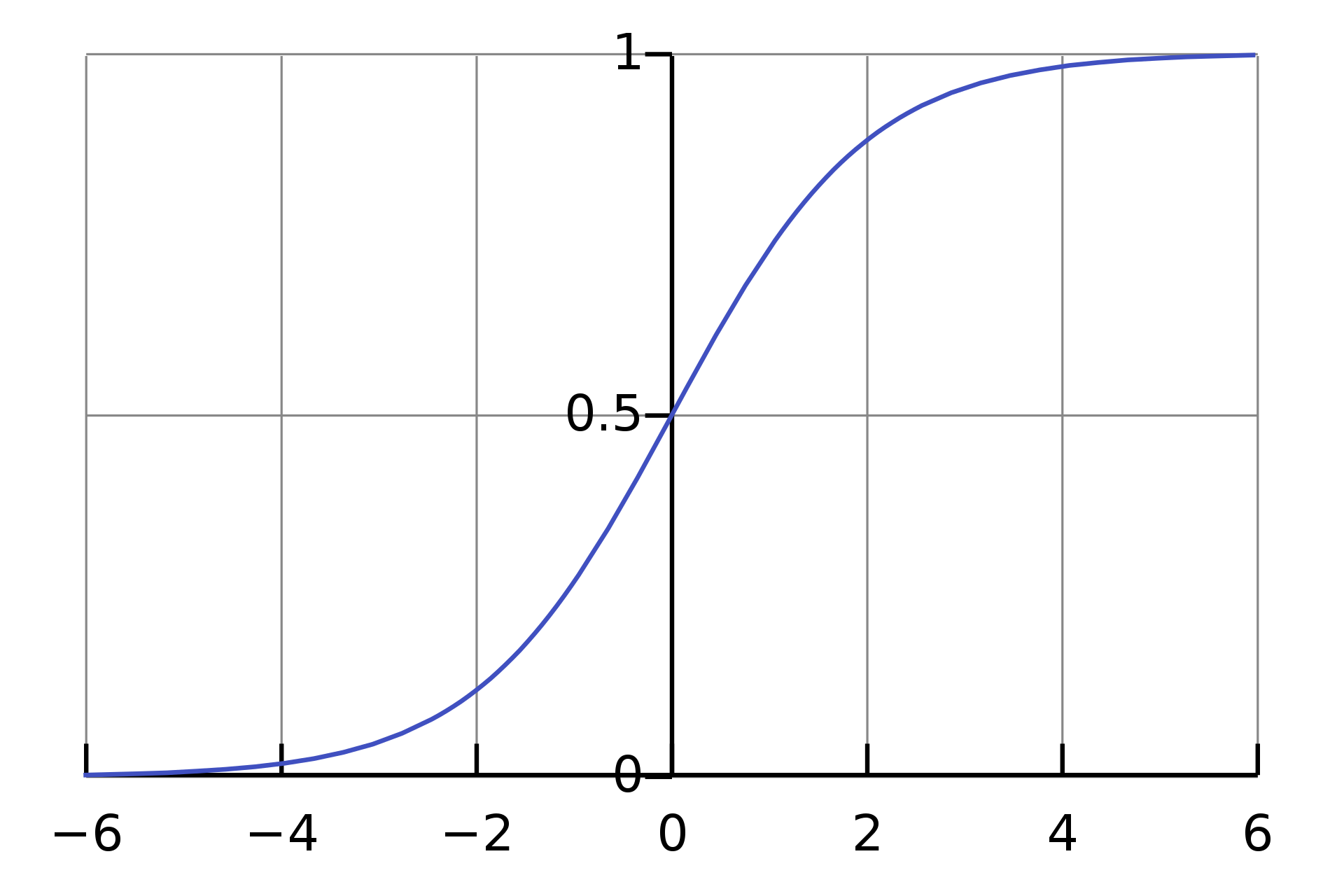
如果控制参数较小,那么中间层输出的参数也会很小,就会集中在中间导数相对于稳定的位置,也就是限制了分类模型过分的扭曲。