代码分块讲解。分析Ajax请求来爬取今日头条的图集,将结果存储在MongoDB中。使用了Python多进程(multiprocessing)并行进行抓取。针对一个实战的教程进行修改,以适应今日头条最新的网页请求方式
完整代码在这里
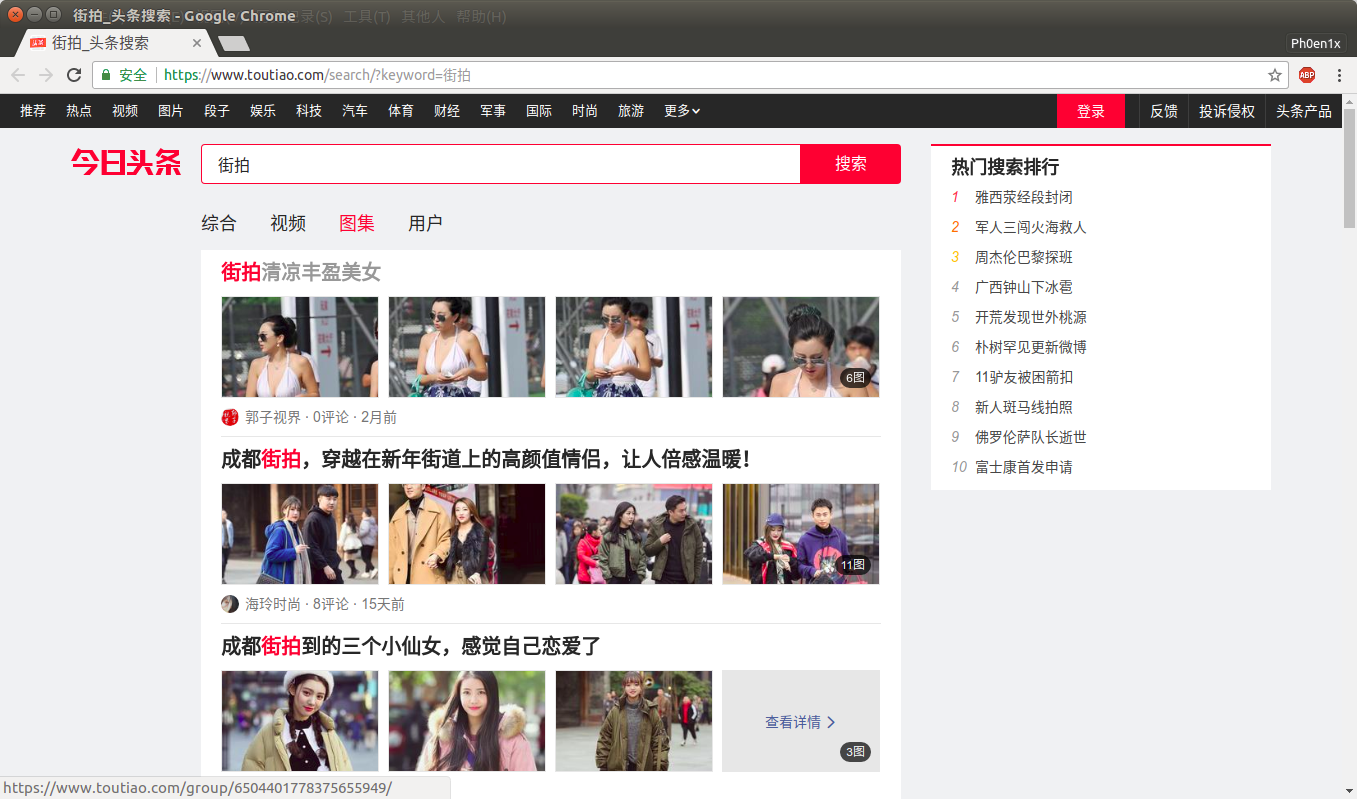
首先,本次要爬取的页面外观如下
搜索后点击图集标签
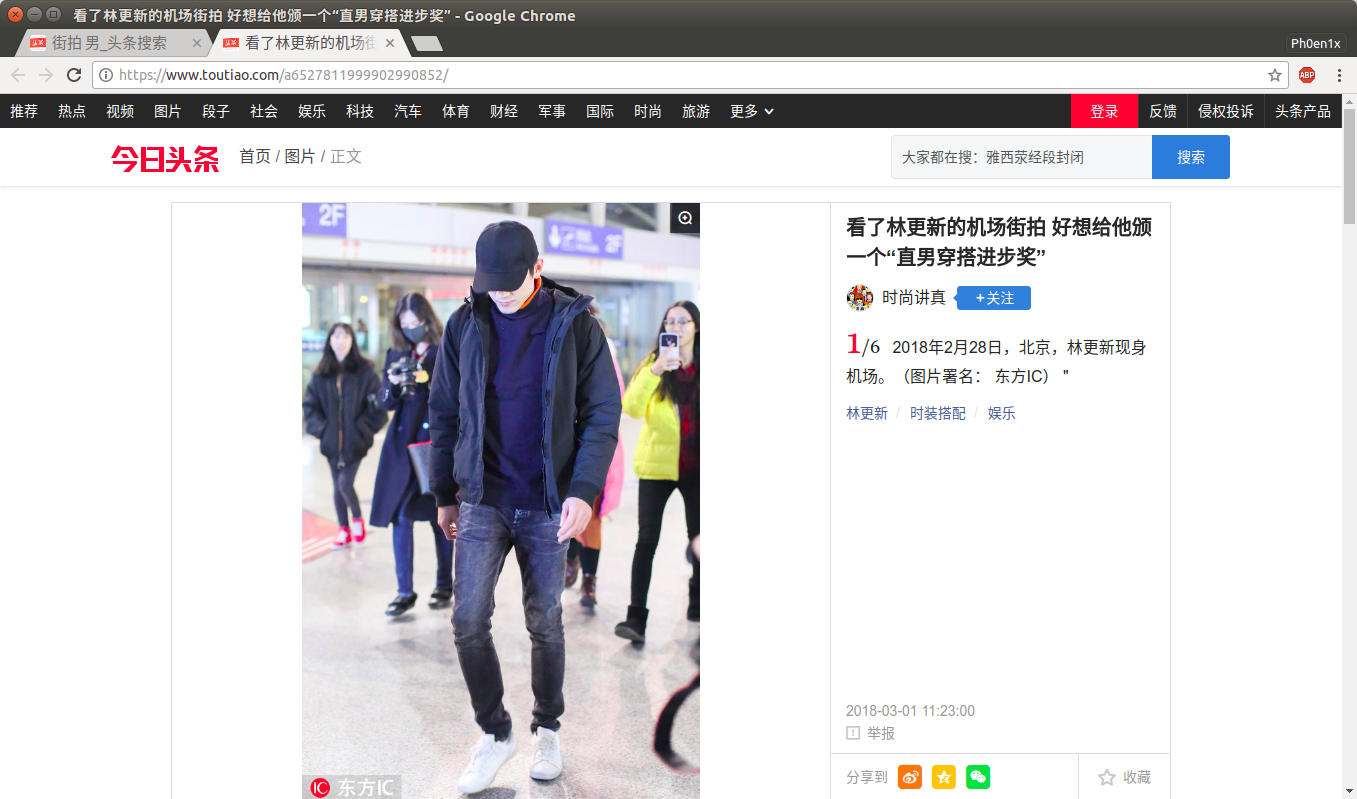
点击进某一个详细页面后,得到:
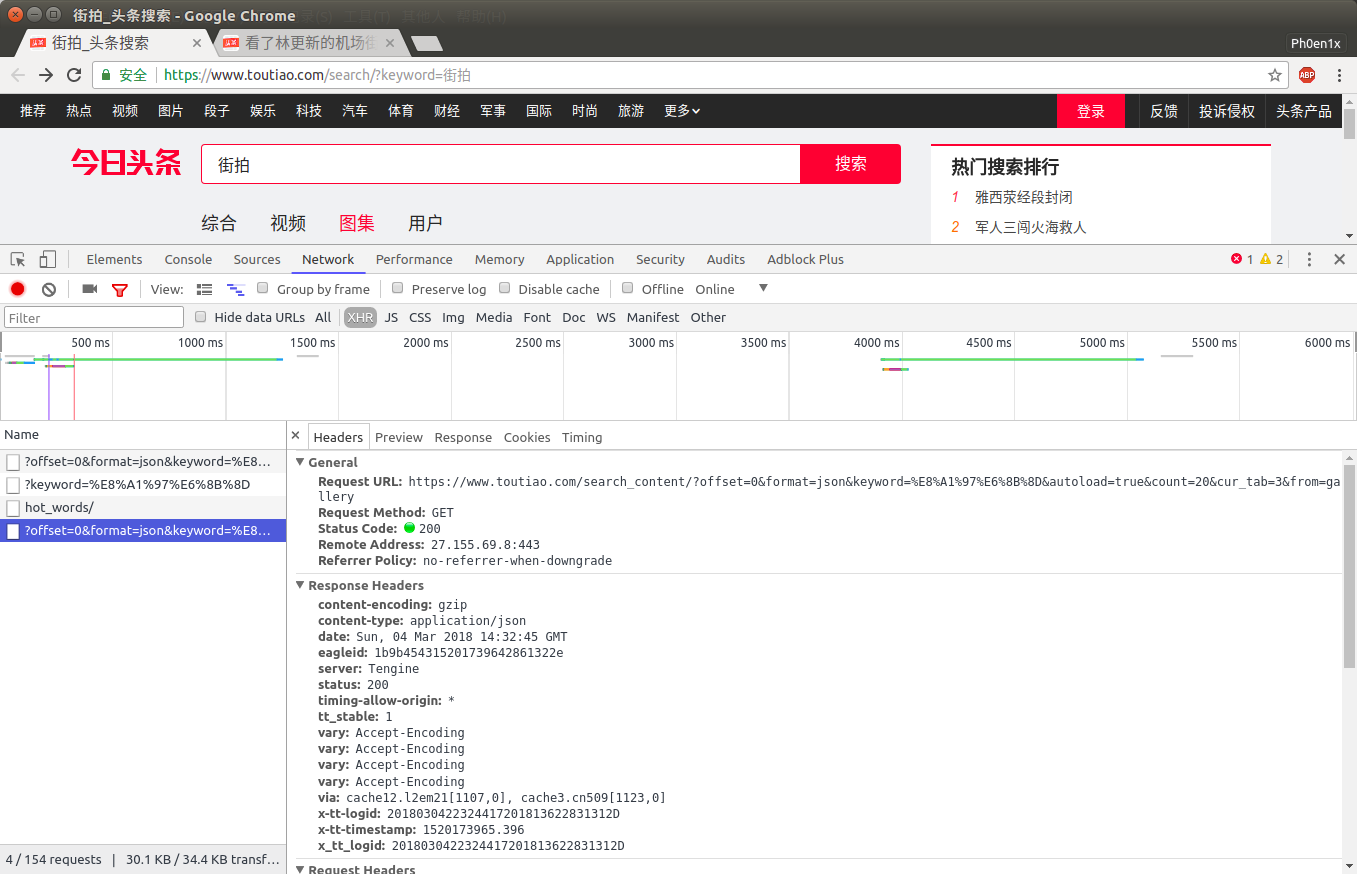
其中所有照片不会一口气全部呈现在页面中,而是通过翻页来使用Ajax请求新的展示图
在搜索结果展示页,打开开发者工具->Network->XHR,然后刷新,我们可以获取请求的URL和请求的参数
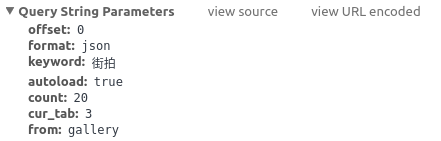
编写获取页面的代码
1 | def get_page_index(offset, keyword): |
从开发者工具可以看到得到的响应串是
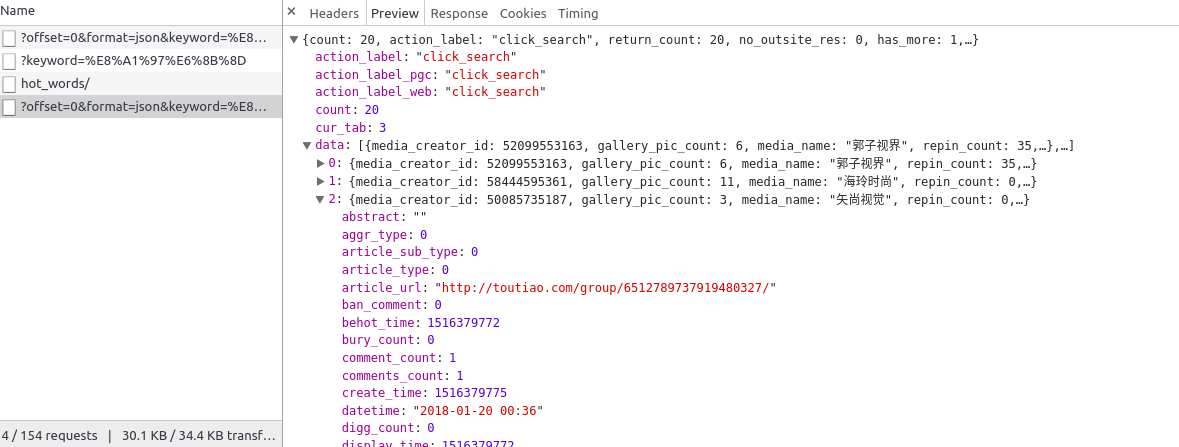
编写获取每个detail页面的url代码
1 | def parse_page_index(html): |
获得每个detail页面的url后,与index页面类似,请求每个url
1 | def get_page_detail(url): |
在每个detail页面中打开开发者工具->Network->Doc,可以看到detail页面都预备要请求什么
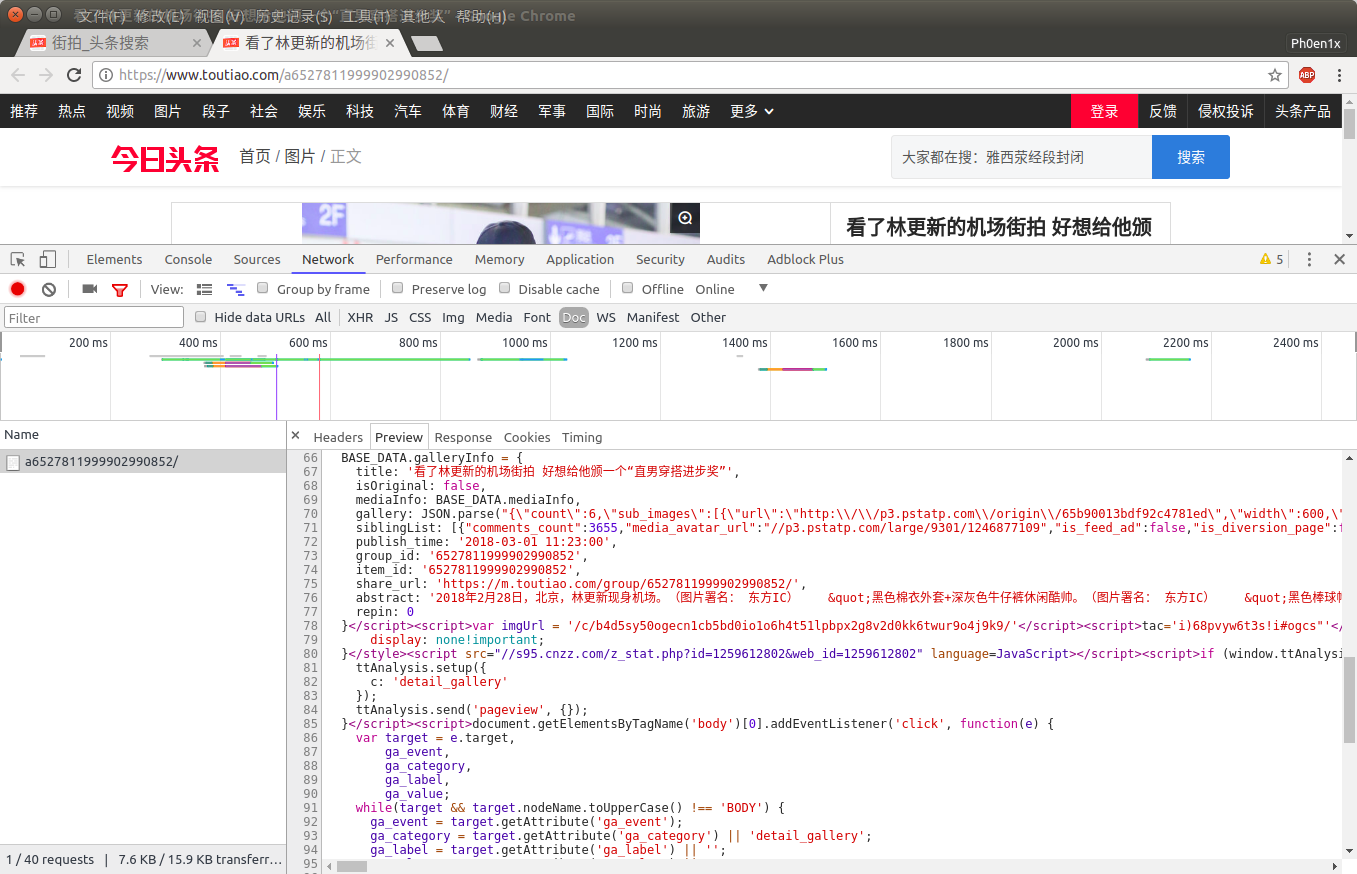
可以发现在BASE_DATA.galleryInfo中gallery里记录了每个sub_img的信息,所以用正则表达式把它们提出来并尝试去请求图片
1 | def parse_page_detail(html, url): |
下载图片同请求网页类似
1 | def download_image(url): |
保存图片
1 | def save_image(response, filename): |
主函数
1 | def main(offset): |
插入数据库的操作
1 | #连接数据库 |
其中
1 | MONGO_URL = 'localhost' |
并行地抓取不同offset的数据
1 | if __name__ == "__main__": |
Enjoy it !!!