LargeVis是唐建在2016年提出的高维数据降维可视化算法,主要工作是大大降低了t-SNE算法的计算复杂度,使算法能够更高的效率处理更大规模的数据。主要使用的优化方法是改进的随机投影树KNN图构造方法以及、与Word2Vec类似的采样与负采样方法以及随机梯度下降算法;在距离的映射方面仍然采用了与t-SNE一样的高斯分布——T分布的策略
高效KNN图构造方法
构造精确的KNN图在计算复杂度上是非常高的,需要计算两两点之间的距离,这需要O(N2d)的复杂度。在t-SNE的后续工作中已经意识到了这个问题,于是Maaten提出了各种随机投影树的算法,详细的算法将在其他的笔记中详细的记录,大致上就是对空间上进行划分直到同一区间内的点少于一个阈值,最后被分在同一块区域中的数据点就被认为是NN。这样来确定近邻效率高了不少,但是为了保证KNN图的精确率,仍然需要创建许多的投影树,这样还是十分影响效率。于是LargeVis中运用了一种叫邻居搜索的方法,主要思想就是“邻居的邻居也是我的邻居”。
首先创建少量的随机投影树先粗略估计KNN,为每个节点维护一个最大堆,然后搜索图每个节点邻居的邻居,这些节点也有可能成为最近邻的候选,与原节点的最大堆比较,若比它小则push若是堆内的节点数超过K,就pop。我们可以多迭代几次来提升图的精确度,实践中只要少量的迭代就可以让精确度接近100%。下图展示了LargeVis构建KNN图的算法流程:

图可视化
在定义好KNN图后,LargeVis同样也需要像t-SNE那样的从高维到低维的映射。
LargeVis在映射的过程中仅保留了KNN边的权重,这些边被称作是正边,而不直接相邻的节点之间称作为负边。正边的边权同t-SNE中定义相同,使用高斯分布进行映射:
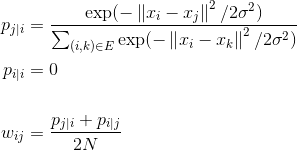
而在低维,则依靠观测的概率来决定低维的坐标:
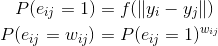
其中f(.)是距离函数,可以使用t分布等距离越小数值越大的函数来做映射,就是高维当中越接近的点,低维当中也要更加的接近。所以最终的优化目标函数:
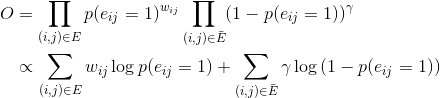
其中两个E是正边集与负边集。
优化
直接按照上述目标函数进行优化开销是很大的,因为负边的数量是非常大的,直接对所有负边进行训练又要造成复杂度的上升。所以这里就要采用负采样算法进行优化。
负采样算法根据对应节点的
度来决定被采样到的概率,即度越大的节点被当作负边的另一个节点的概率越大,概率满足噪声分布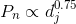
这样一来,目标函数就变成了:
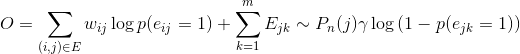
这样一来,目标函数就得到确定,但是,如果直接使用边的权重进行训练,权重直接乘到梯度中,不同边的权重不同,会对梯度造成很大的影响,权重较大的边受到的变动步长也较大,会影响训练过程。所以这里要用到LINE技术,将带权边看作wij条单位边,这样一来就可以直接对所有的正边进行采样,对目标函数也没有改变
此外就是异步随机梯度下降算法,因为构建的KNN图非常的稀疏,同时对几个点进行梯度下降,一般不会重叠产生冲突,这样就能大大提高训练效率
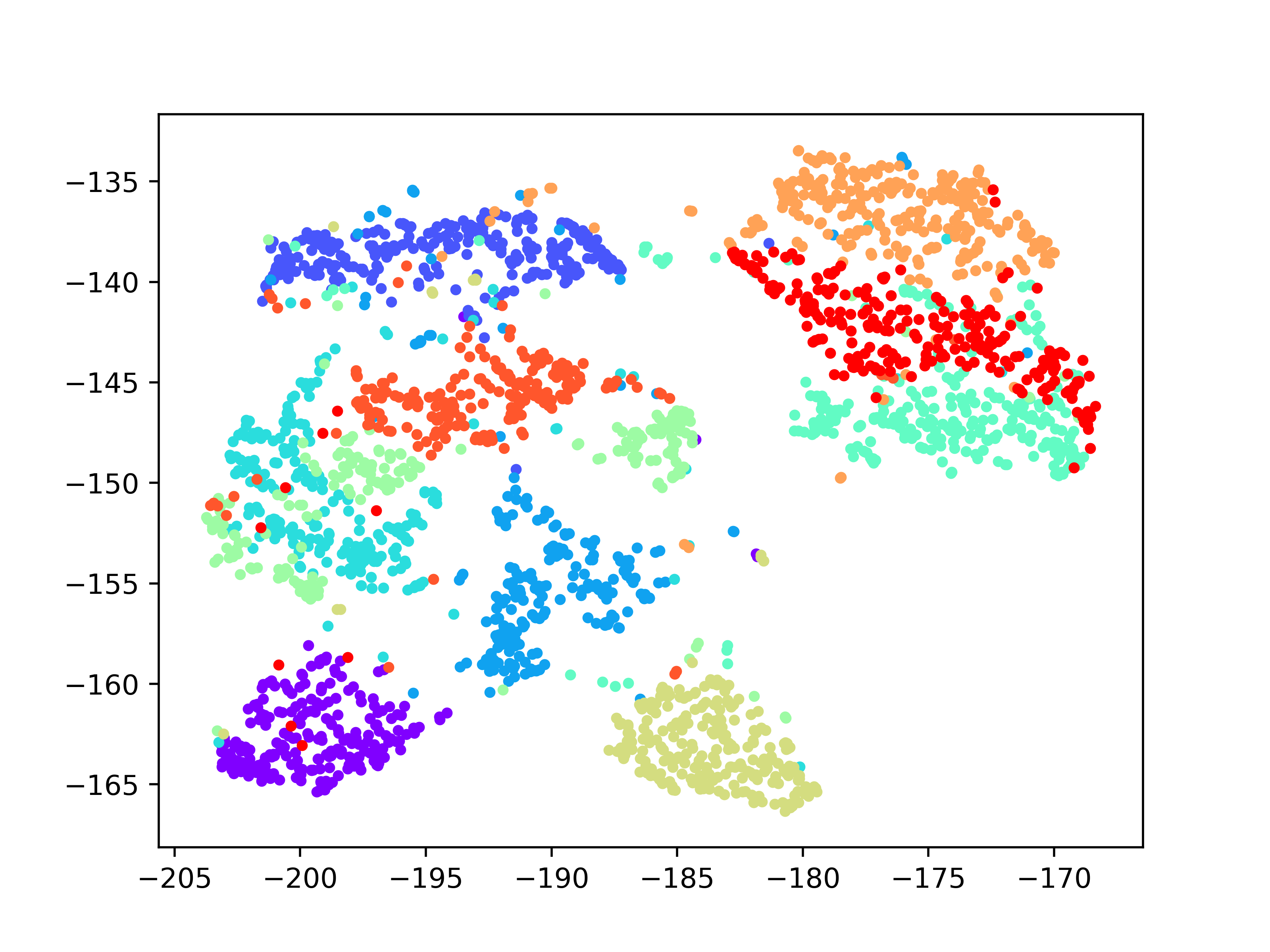
结果
LargeVis的结果还是很接近tsne的,而且处理速度能快不少(没有用官方给的MNIST数据集,所以和他们给的结果不大一样)。