这三种数据集合非常容易弄混,特别是验证集和测试集,这篇笔记写下我对它们三个的理解以及在实践中是如何进行划分的。
训练集
这个是最好理解的,用来训练模型内参数的数据集,Classfier直接根据训练集来调整自身获得更好的分类效果
验证集
用于在训练过程中检验模型的状态,收敛情况。验证集通常用于调整超参数,根据几组模型验证集上的表现决定哪组超参数拥有最好的性能。
同时验证集在训练过程中还可以用来监控模型是否发生过拟合,一般来说验证集表现稳定后,若继续训练,训练集表现还会继续上升,但是验证集会出现不升反降的情况,这样一般就发生了过拟合。所以验证集也用来判断何时停止训练
测试集
测试集用来评价模型泛化能力,即之前模型使用验证集确定了超参数,使用训练集调整了参数,最后使用一个从没有见过的数据集来判断这个模型是否Work。
三者区别
形象上来说训练集就像是学生的课本,学生 根据课本里的内容来掌握知识,验证集就像是作业,通过作业可以知道 不同学生学习情况、进步的速度快慢,而最终的测试集就像是考试,考的题是平常都没有见过,考察学生举一反三的能力。
为什么要测试集
训练集直接参与了模型调慘的过程,显然不能用来反映模型真实的能力,这样一些 对课本死记硬背的学生(过拟合)将会拥有最好的成绩,显然不对。同理,由于验证集参与了人工调参(超参数)的过程,也不能用来最终评判一个模型,就像刷题库的学生也不能算是学习好的学生是吧。所以要通过最终的考试(测试集)来考察一个学(模)生(型)真正的能力。
但是仅凭一次考试就对模型的好坏进行评判显然是不合理的,所以接下来就要介绍交叉验证法
交叉验证法
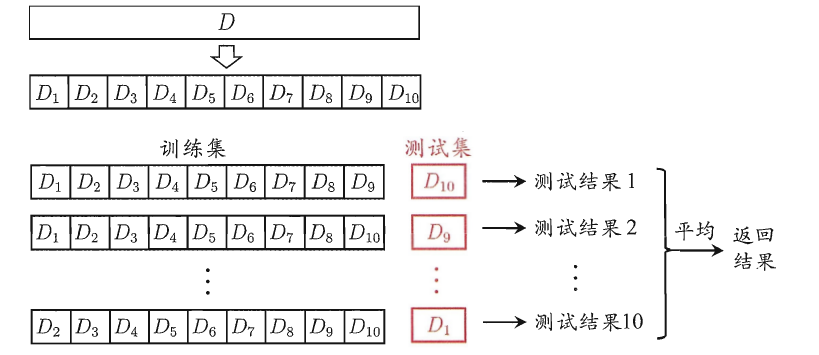
交叉验证法的作用就是尝试利用不同的训练集/测试集划分来对模型做多组不同的训练/测试,来应对单词测试结果过于片面以及训练数据不足的问题。
交叉验证的做法就是将数据集粗略地分为比较均等不相交的k份,即
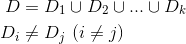
然后取其中的一份进行测试,另外的k-1份进行训练,然后求得error的平均值作为最终的评价,具体算法流程西瓜书中的插图如下: