word2vec模型与应用由Mikolov等人在自然语言领域具有很高的影响,它在语言模型进行学习前先找寻到一种合适的编码方式,这种编码方式叫作词嵌入(Word Embedding); 本片笔记属于原理介绍,没有实现细节的代码讲解
One-hot编码
嵌入前通常会使用 one-hot编码方式,这种编码方式每个词都会单独的占一位,该位为1则表示这个词出现,例如但前语料中一共有5个词,那么它们就分别表示为10000,01000,00100,00010,00001。
显然,这是一种极不高效的编码方式,既需要极大的空间用于存储,也不能从词向量中获得有用的词之间的语义关系,这也就是为什么需要词嵌入技术的原因。
Why word2vec?
为什么Word2Vec方法受到如此多的注意,以至于对现在的自然语言处理产生了极大的影响?
总结了一下Word2Vec的几个特点:
快,以往的词嵌入得到的词向量仅仅只是一个副产物,而w2v则针对词嵌入提出了各种模型以及相应的优化算法(后面会提到的)
语义上相近的词向量相似度上也比较接近
这点是最神奇的,虽然不知道为什么,w2v得到的词向量竟然满足语义上的加减法!!!比如
Madrid-Spain+France=Paris;king-man+women=queen; (⊙ω⊙)!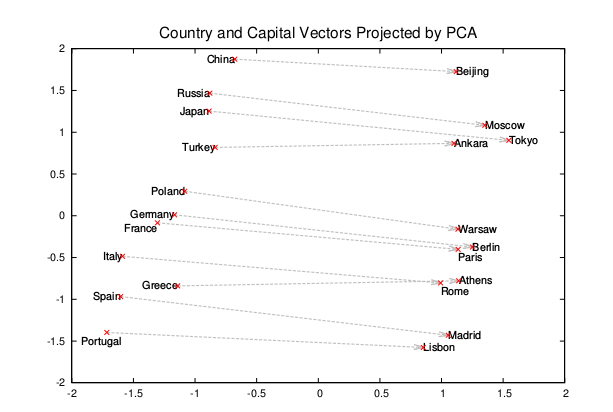
此外w2v还拥有两种模式Skip-gram与CBOW,而每种模式下都有两种优化的实现方法Hierarchical Softmax, Negative Sampling
Skip-gram
第一种模式是Skip-gram模式,根据一个词推测出其最有可能的上下文(Context),其结构图如下:
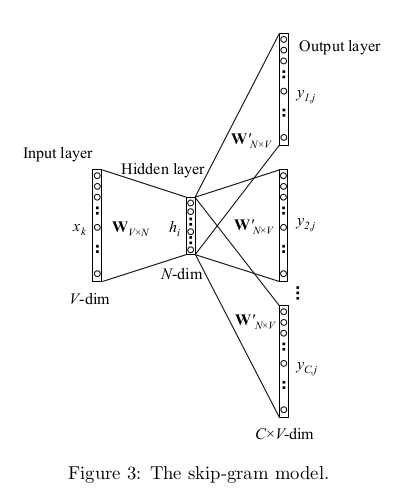
步骤
- 输入One-hot编码,每个词向量现在都是V维的,V就是语料中词汇的总数
- 乘上字典矩阵WV*N,变成一个N维向量。N就是嵌入后的词向量维数
- 乘上字典矩阵W’N*V,相当于求距离,然后再求一个Softmax,变成一个V维向量。每一位其实都代表改为one-hot编码的词出现的概率
CBOW
CBOW(Continuous Bag-of-Words),是另外一种Word2Vec的模式,用于根据上下文推测出空缺的词的方法,其结构示意图如下:
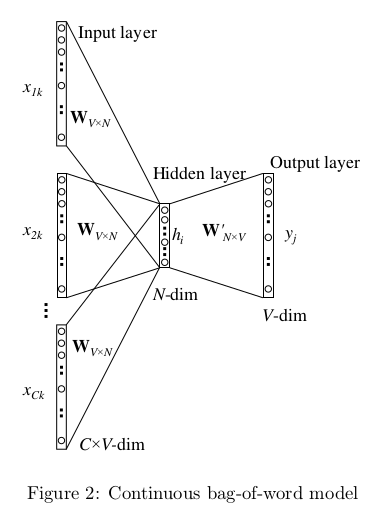
步骤
输入上下文C个词的One-hot编码
乘上字典矩阵WV*N,得到各自的N维编码
取它们的平均值
乘上字典矩阵W’N*V,相当于求与其他词之间的距离,然后取Softmax,变成一个V维向量,每位代表的还是这个位上one-hot编码的那个词的概率,选最大的那个
Hierarchical Sotfmax
上面说的就是Word2Vec的基本思想了,但是呢,当语料非常庞大的时候,求Softmax
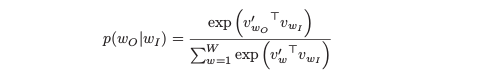
开销就会变得异常的大,其中一种解决方法就是使用层次Softmax(Hierarchical Sotfmax)来将Softmax的概率转化为一个多次二分类问题。
层级Softmax函数使用的数据结构是以词频作为权重构造的霍夫曼树(Huffman Tree),这样做的好处是词频大的词只需要更少的遍历就可以找到
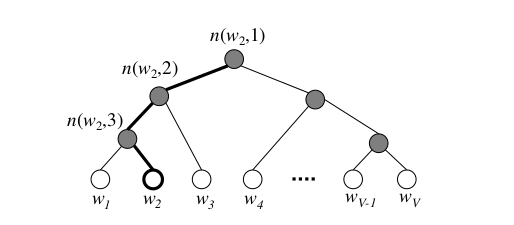
叶子节点为V个语料中的词,而非叶子节点也有一个向量v,代表一次选择,即每走一步都需要确定下一步是要走到左孩子节点还是右孩子节点,原来的Softmax概率就被写成
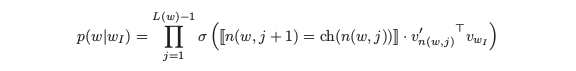
σ(*)是Sigmoid函数,双竖线中括号表示若选择左孩子则为1,右孩子则为-1,在sigmoid中正好正负样例两者 相加等1。最后就是非叶子节点向量与词向量的内积。训练时同时考虑词的嵌入向量训练和霍夫曼树上非叶子节点的参数。
- 与CBOW配合,将叠加以后的嵌入向量作为霍夫曼树的输入,去寻找原中心词,并以此过程优化霍夫曼树与词向量;
- 与Skip-Gram配合,将目标词汇一个个作为霍夫曼树的输入 ,去寻找原中心词,并以此过程优化霍夫曼树与词向量;
Negative Sampling
在此前的LargeVis–LINE在高维数据降维与可视化上的运用中已经提到了Negative Sampling,实际上,在Word2Vec后,负采样技术在运用上比层级Softmax更加的广泛。
做法也与LargeVis相似,即使得正样本出现的概率最大,负样本出现的概率减小,那么如何取负样本呢?
将所有的词按照词频的3/4次方为正比进行采样作为负样本,即满足概率:
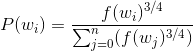
按照这个概率取得负样本(若取到中心词本身则重新进行采样)用于替换中心词,与原中心词的Context组成一组负样本,只要取几个词就可已完成负采样。按照原文的话说,当数据集比较小的时候,5-20个负样本; 当数据集比较大的时候,只需要2-5个就可以了。
负采样的目标函数为:
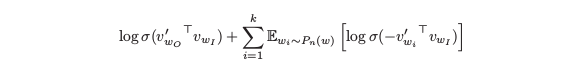
高频词子采样
语料中总是有很多类似于”a” “the” “in”这样的词,这些词被认为不会提供太多有用的信息,因为它们几乎会出现在所有的词的context中。所以对于这些词我们进行子采样(Subsampling)来进行过滤。Mikolov的原文中采用的下采样公式是
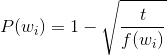
P是每个词被删除的概率,t是一个认为定的阈值,大约在10-5左右,f是词频。这样一来,稀有的词就能得到保留,而频繁出现的词却会被大面积的删除,但总体词频的顺序不变,达成下采样的目的。
Tensorflow实现
负采样Skip-gram word2vec Tensorflow封装实现
参考
Distributed Representations of Words and Phrases and their Compositionality
word2vec Parameter Learning Explained