参考文献:Ongaro D, Ousterhout J K. In search of an understandable consensus algorithm[C]//USENIX Annual Technical Conference. 2014: 305-319.
一、Raft简介
Raft的作者认为Paxos即使经过几次的重新描述,但依旧让人难以理解,同时Paxos在提出过程中大多数都集中于单提案的模型,没有对实际应用做太详细的规定,因此过于理论化,在实际投入生产过程中,还是必须要提出许多变体来对相对应的应用场景做相应的优化。所以他提出了一套更加容易理解、更适合工业实践和教学的一致性算法。因此Raft算法的设计目标就是易理解,让人更容易理解算法流程和设计目的。
Raft将每个服务器都看作一个状态机(state machine),每个状态机中都维护着一个日志,客户机向一个状态机提交一个请求,也就是向对应的状态机的日志添加了个带有命令的log entry。Raft算法维护所有服务器中的日志保持一致。这样所有的状态机都按照相同的顺序执行所有的操作,输出相同的输出。
Raft中也是分为三种不同的角色,而且与Paxos一样,角色也并非与服务器一一对应,而是动态改变的,一台服务器可能因为某些事件的触发而产生角色的变动。但是,每个角色所需要执行的操作却大不相同,三种状态间的转换如图1所示: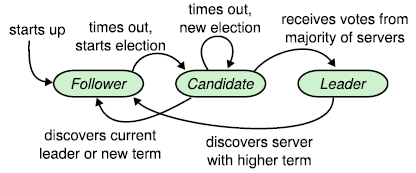
- 领导者(Leaders)
Raft引入了领导者这一角色,但这个想法并不是Raft最早提出的,早在Paxos的变体multi-paxos中已经有类似角色的体现。
同时,Raft中使用任期(term)的概念。这一概念与Paxos中的number这一概念一样都充当了逻辑时钟的作用。在每一个任期的开始需要选出至少一个领导者(某些情况下一个任期内的所有候选者都竞选失败,没有领导者产生),然后由领导者来控制后续的日志复制(log replication)。理论上只要当前的领导者服务器没有发生故障或者因为连接中断,任期可以无限长。在领导者失效时,为了防止单点失效的问题,Raft会重新在新的任期中进行一次选举来保证系统依旧可用。日志在Paxos当中相对应于提案,而复制日志相当于Paxos中确认提案与学习提案。但是,新的log只能由领导者提出,也就是客户端直接向领导者提出申请,然后由领导者去通知其他机器新的log和提交确认。 - 候选者(Candidates)
候选者是一个中间状态,跟随者要想成为领导者,必须要先声明成为候选人,然后进行选举,请求其他服务器为自己投票,赢得由其他的跟随者投票,最终成为领导者,若在竞选中失败,则只能变回跟随者。 - 跟随者(Followers)
跟随者有点像是Paxos中的学习者,被动地接受他人提出的变动。但是却和Paxos中的学习者不完全一样,Raft中的跟随者还有一个重要的任务,就是检查候选者的合法性以及给合法的候选者投票,让他们成为领导者。
根据上面的一些设定,Raft一共研究的就是三个子问题:
- 如何选举领导者,当现有的领导者失效的情况下,如何选出新的领导者,选举领导者的时候如何确定新的领导者不会破坏安全性原则
- 如何进行日志的复制,什么时候可以保证日志可以安全提交
- 如何保证系统的安全性,要维护包含以下的几个性质:
- 选举安全性:每一个任期(term)内只能有一个服务器被选举为领导者。
- 领导者只做append操作:领导者的所有的日志entry只能append在队列尾,而不能删除和覆盖。
- 日志匹配:如果两个日志在相同的序号上的日志entry的任期相同,那么这个日志从头到这个序号之间的日志entry时完全相同的。
- 领导者完整性:在一个领导者上提交的日志entry,在后面的term的领导者中也必须出现。也就是说,只有同步了最新log的server才能够被选举为领导者。
- 状态机安全性:如果一个服务器已经执行了日志上某个entry中的指令,那么其他服务器上相同序号不同的日志entry将不能够执行。
二、领导者选举
整个过程的第一步是选举领导者,在系统刚刚启动时或者是当现有的领导者失效时,都将会触发这个过程。当一个跟随者一段时间(所有跟随者都会设置一个一定区间内的随机的计时周期,election timeout)内没有收到来自领导者定时发送的心跳(Heartbeat)或是其他候选者发送来的投票请求时(其他服务器竞选请求也会阻止一个跟随者成为候选者),就会为自己开始一轮选举。开始选举主要需要以下步骤:
- 自己所知道的任期+1
- 给自己投一票
- 同时给所有人发送投票请求
规定所有的跟随者只能投第一个收到的请求一票。当候选者收到半数请求的确认回复时,则赢下了这次选举,将自己的状态改为领导者,并向其他所有服务器开始广播自己的心跳,告知新的任期的开始,以确保其他服务器不会开始新的选举。
在候选者还在等待投票的时候,若收到一个任期不小于自己的其他领导者的心跳,说明已有其他候选者赢得了选举(若任期比自己小,可能是原来被网络阻隔的领导者的包达到了,在这种情况下,可以继续进行选举,等待选举胜利之后取代原来的领导者),那么将放弃这次选举,将状态改回跟随者(不用改回任期,因为当前的新领导者的任期不会小于自己,他会通知自己以及其他所有的服务器将自己的任期进行更新)。
另一种情况是,同时有两个及以上的候选者产生,他们同时发出了投票请求,这样很可能就都得不到半数以上的投票。这种情况下候选者会在等待超时后重新执行一遍上述三步的流程,直到有一个领导者获胜,而election timeout的随机性也避免了这一情况的反复发生。
三、日志复制
按照上一章的领导者选举过程顺利完成领导者选举之后,胜出的领导者就开始接受客户端的请求。接收客户端请求后,领导者会在自己的状态机上append上包含最新命令的log entry,并通过AppendEntries远程过程调用(RPC),将这个log entry同步到其他服务器上。当超过半数的服务(包括自己)应答append成功后,领导者会在状态机上确认提交这个命令并将结果返回给客户机,同时通知其他服务器提交这个命令。
然而,在复制日志的过程中,会出现各种各样的问题,图2展示了多种领导者与跟随者上日志不一致的情况。例如跟随者缺失一些日志(a-b),也有可能多出一些(c-d),也有可能即少一些又多一些(e-f)。例如当服务器在作为跟随者的时候崩溃或网络连接错误,就有可能造成日志的缺失。当作为领导者时的崩溃或网络连接错误而没有将用户提交的请求进行同步,就有可能造成未提交的日志的多出。而实际中情况可能更加复杂。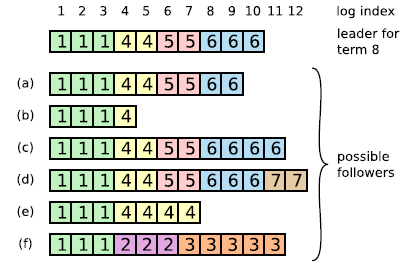
为解决上面这种不一致的情况,领导者在同步日志的时候,需要进行一些一致性检测。上面提到,只要两个服务器日志内的某条entry的任期和序号都一致。那么领导者只需要记下每个服务器当前还未同步日志序号(nextIndex),然后将这个位置之后的日志发送过去,并在AppendEntrie请求中带上自己的任期,跟随者就可以根据送来的日志内的任期和序号以及领导者的任期,检查自己是否能够同步这些日志。如果不能同步,那么跟随者将会将自己所需要的日志号发送回给领导者,让领导者调整对自己的nextIndex,最终就能保证日志的一致。
但是,这样还不能保证领导者完整性。存在这样一种情况,在前一个任期内网络连接断开而没有同步某些已提交日志entry的某个跟随者,在新的任期中成功当选。显然让这样的服务器成为领导者是不安全的,因为他会覆盖掉原来已经提交的log(Raft的日志只能由领导者同步到跟随者上,不能指望跟随者告诉领导者他的缺失)。所以Raft在选举的时候设置了一个机制,跟随者需要检查当前候选者的已提交日志是否比自己的要旧,若是更旧则不能投票给他让他当选。由于所有日志的提交都需要至少有半数以上的服务器的通过,所以这一机制也就保证了提交日志记录不是最新的服务器无法成功当选领导者。
四、总结
Paxos与Raft都是为解决分布式系统中一致性问题而提出的一致性算法。不同的是,Paxos更加偏向理论解释而Raft更偏向于实现。虽然本篇笔记所阅读的Paxos的论文只讨论了Paxos的最基础部分,但仍然能够看出其原理描述的优美精妙,让人切实地体会到算法的简洁有效,也是因为这些让Paxos在过去的十年间几乎成为了一致性算法的代名词。而Raft更加注重于可理解性和实现方面,在算法为何有效方面阐述的较为直白清晰。但Raft体现的细节较多,对每一种可能出现的情况都逐一进行讨论并说明给出的解决方案。