本篇笔记介绍深度学习中最简单的三种优化算法,SGD,Momentum,Nestrov的理解与实现
一、SGD
随机梯度下降法不用多说,每一个参数按照梯度的方向来减小以追求最小化损失函数
更新方式
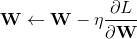
Python实现
1 | class SGD: |
二 、Momentum
在梯度下降的基础上加入了动量,即前面的梯度将会影响本轮的梯度方向
更新方式
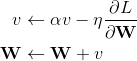
Python实现
1 | class Momentum: |
三、Nestrov
Nestrov也是一种动量更新的方式,但是与普通动量方式不同的是,Nestrov为了加速收敛,提前按照之前的动量走了一步,然后求导后按着梯度再走一步
更新方式
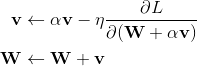
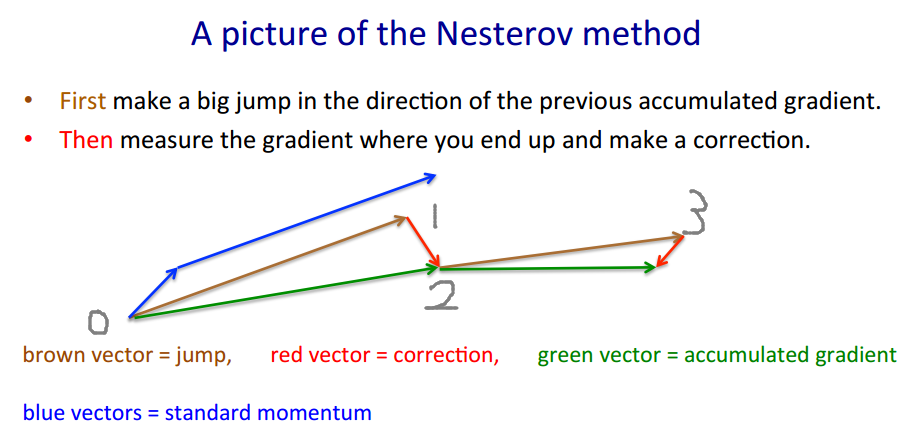
但是这样一来,就给实现带来了很大的麻烦,因为我们当前是在W的位置上,无法求得W+αv处的梯度,所以我们要进行一定改变。由于W与W+αv对参数来说没有什么区别,所以我们可以假设当前的参数就是W+αv。就像下图,按照Nestrov的本意,在0处应该先按照棕色的箭头走αv到1,然后求得1处的梯度,按照梯度走一步到2。
现在,我们假设当前的W就是1处的参数,但是,当前的动量v仍然是0处的动量,那么更新方式就可以写作
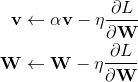
这样一来,动量v就更新到了下一步的2处的动量。但是下一轮的W相应的应该在3处,所以W还要再走一步αv,即完整的更新过程应该如下所示:
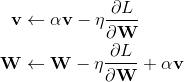
第二行的v是第一行更新的结果,为了统一v的表示,更新过程还可以写作:
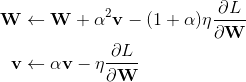
Python实现
1 | class Nestrov: |
但是根据我看到的各个框架的代码,它们好像都把动量延迟更新了一步,所以实现起来有点不一样(或者说是上下两个式子的顺序进行了颠倒),我也找不到好的解释,但是再MNIST数据集上最终的结果要好于原来的实现。
Python实现
1 | class Nestrov: |
四、AdaGrad
前面介绍了几种动量法,动量法旨在通过每个参数在之前的迭代中的梯度,来改变当前位置参数的梯度,在梯度稳定的地方能够加速更新的速度,在梯度不稳定的地方能够稳定梯度。
而AdaGrad则是一种完全不同的思路,它是一种自适应优化算法。它通过每个参数的历史梯度,动态更新每一个参数的学习率,使得每个参数的更新率都能够逐渐减小。前期梯度加大的,学习率减小得更快,梯度小的,学习率减小得更慢些。
更新过程为
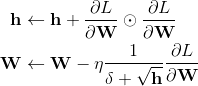
其中δ用于防止除零错
Python实现
1 | class AdaGrad: |
五、RMSprop
AdaGrad有个问题,那就是学习率会不断地衰退。这样就会使得很多任务在达到最优解之前学习率就已经过量减小,所以RMSprop采用了使用指数衰减平均来慢慢丢弃先前得梯度历史。这样一来就能够防止学习率过早地减小。
更新过程如下:
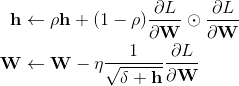
Python实现
1 | class RMSprop: |
六、Adam
Adam方法结合了上述的动量(Momentum)和自适应(Adaptive),同时对梯度和学习率进行动态调整。如果说动量相当于给优化过程增加了惯性,那么自适应过程就像是给优化过程加入了阻力。速度越快,阻力也会越大。
Adam首先计算了梯度的一阶矩估计和二阶矩估计,分别代表了原来的动量和自适应部分
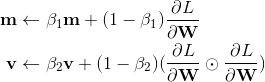
β_1 与 β_2 是两个特有的超参数,一般设为0.9和0.999
但是,Adam还需要对计算出的矩估计进行修正
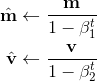
其中t是迭代的次数,修正的原因在Why is it important to include a bias correction term for the Adam optimizer for Deep Learning? 这个问题中有非常详细的解释。
简单来说就是由于m和v的初始指为0,所以第一轮的时候会非常偏向第二项,那么在后面计算更新值得时候根据β_1 与 β_2的初始值来看就会非常的大,需要将其修正回来。而且由于β_1 与 β_2很接近于1,所以如果不修正,对于最初的几轮迭代会有很严重的影响。
最后就是更新参数值,和AdaGrad几乎一样,只不过是用上了上面计算过的修正的矩估计
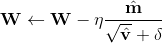
python实现
1 | class Adam: |
七、参考
《Deep Learning》花书
《深度学习入门——基于python的理论与实现》