图结构数据是除了图片、文本、语音之外又一常见且重要的数据类型,例如社交网络数据、引用网络数据、和生物蛋白质数据等等。在针对图像、文本等数据的机器学习任务中,都有相对应的方法,将这些数据中的特征用一个稠密向量进行表示,然后再运用于各种各样的任务中去。网络表示学习就是将网络中结点的特征,嵌入(Embedding)至低位向量中的方法。学习到的这些向量将会保留图结构数据结点的相似性,使得一些下游机器学习任务,例如结点分类、结点聚类、连接预测、可视化等等的模型泛化性能得到增强。
本文首先将会介绍网络表示学习最为著名的四份工作:DeepWalk、LINE、Node2Vec和SDNE。
然后将会介绍两篇在AAAI18上的两篇网络结构表示学习的新工作HARP、GraphGAN
本文首发于知乎专栏:SoftWiser
一、DeepWalk: Online Learning of Social Representations
DeepWalk可以称得上是这个方向上最著名的工作了,几乎所有网络表示学习相关的论文,都会引用DeepWalk作为Baseline之一,同时DeepWalk也是很多相关工作所使用的底层方法之一。可见这份工作在网络表示学习领域的地位。
Method
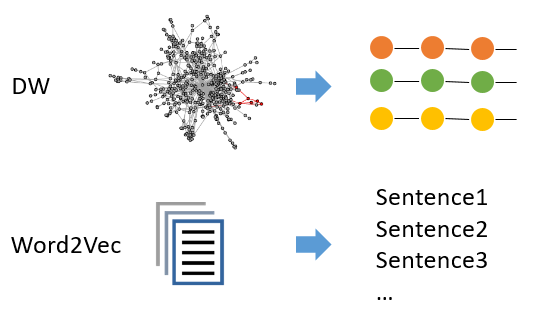
DeepWalk最主要的贡献就是他将Network Embedding与自然语言处理中重要的Word Embedding方法Word2Vec联系了起来,使得Network Embedding问题转化为了一个Word Embedding问题。
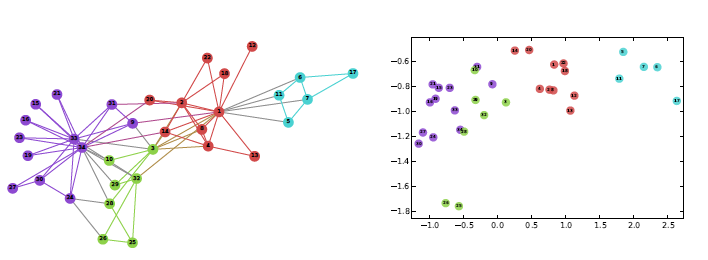
转化方法其实很简单,就是随机游走。如下图所示,DeepWalk通过从每个结点出发n_walks次,每一步都采取均匀采样的方式选择当前结点的邻接结点作为下一步的结点随机游走。当游走的路径长度达到walk_length后,停止一次游走。这样就生成了一个个游走的序列,每个序列都称为一个walk。每个walk都被当成Word2Vec中的一个句子,而每个结点都是Word2Vec中的一个词。
之后的算法几乎和Word2Vec的Skipgram版本完全一样。使用一个大小为window_size的滑动窗口作为一条walk的context,使用一个context中的中心词去推测所有context中的其他词,使用的目标函数也与Word2Vec一致。
Experiments
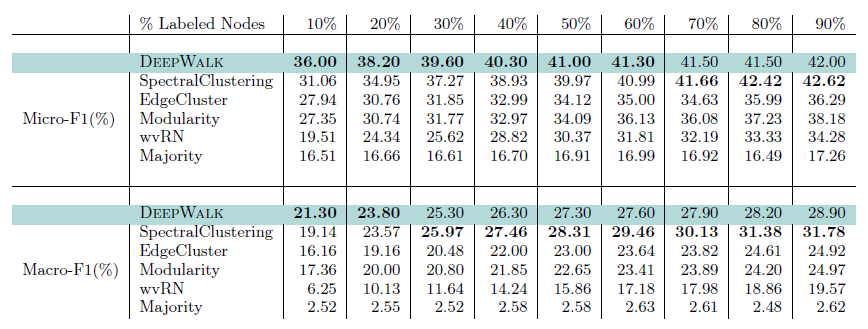
DeepWalk选择Multi-Label Classification作为评价算法Performance的指标。评价中将通过DeepWalk学习获得的Embedding按照不同的比例划分为训练集与测试集。训练集作为N个one-vs-rest对率回归分类器的训练数据,将其中置信度最高的k个类别作为结点的预测类别。其中N为类别的个数,k为结点的标签数。
实验结果如下所示:
二、LINE: Large-scale Information Network Embedding
虽然DeepWalk通过随机游走的方式,将图结构数据转化为了自然语言处理的任务来完成。但是,图结构中节点的关系往往比词上下文关系更加的复杂。通常部分的图结构数据中边具有权重,使用现有的Word2Vec方法无法很好的应对这个问题。此外,在现实世界数据中,图的规模往往过于庞大,以至于存下所有的walk的开销将十分惊人。
Method
LINE不再采用随机游走的方法。相反,他在图上定义了两种相似度——一阶相似度与二阶相似度。
- 一阶相似度:一阶相似度就是要保证低维的嵌入中要保留两个结点之间的直接联系的紧密程度,换句话说就是保留结点之间的边权,若两个结点之间不存在边,那么他们之间的一阶相似度为0。例如下图中的6、7两个结点就拥有很高的一阶相似度。
- 二阶相似度:二阶相似度用一句俗话来概括就是“我朋友的朋友也可能是我的朋友”。他所比较的是两个结点邻居的相似程度。若两个结点拥有相同的邻居,他们也更加的相似。如果将邻居看作context,那么两个二阶相似度高的结点之间拥有相似的context。这一点与DeepWalk的目标一致。例如下图中的5、6两点拥有很高的二阶相似度。
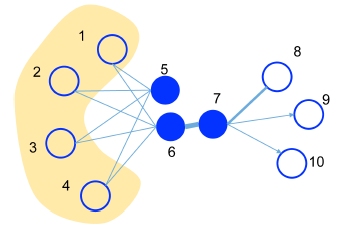
LINE的目标就是保留这两种相似度。
LINE的一阶相似度
两个结点实际的一阶相似度表达如下:
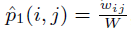
其中W是所有边权重之和。而两个结点embedding之间的相似度为:
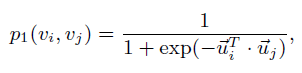
其中u是结点的embedding。即两个结点表示的内积套上一个 对率函数的结果。这样一来目标函数设为实际相似度与表示相似度之间的KL散度就可以了,这样一来,只要最小化KL散度(下式中约去了一些常数),就能保证表示相似度尽量接近实际相似度。
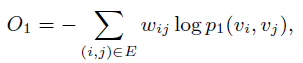
LINE的二阶相似度
两个结点实际的二阶相似度表达式如下:
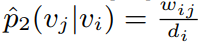
其中wij是边ij的权重,di是结点i的出度。两个结点embedding的相似度为:
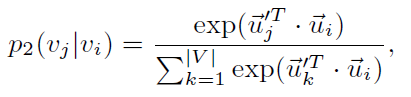
其中V为结点i的所有邻居,这里与一阶相似度不同的地方是,对于邻居结点,使用了另一组的embedding,称作context。目标函数依旧是KL散度,也就是最终,拥有相似邻居的结点,将会拥有相近的embedding。
最终要获得同时包含有一阶相似度和二阶相似度的embedding,只需要将通过一阶相似度获得的embedding与通过二阶相似度获得的embedding拼接即可。
Experiments
同样也来看一下LINE在结点分类任务中的表现:
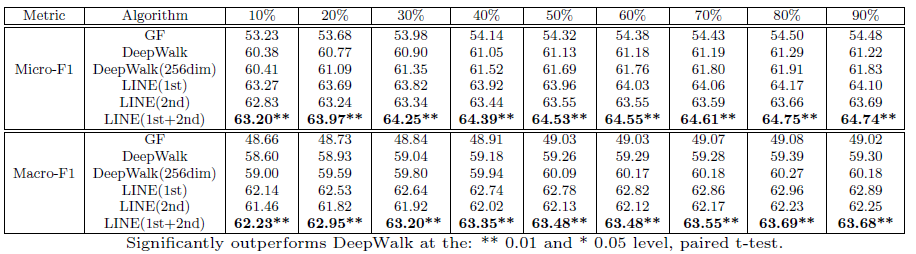
可以看到,当考虑到一阶相似度之后,也就是边的权重后,LINE的表现效果要略好于DeepWalk。
三、Node2Vec: Scalable Feature Learning for Networks
Node2Vec是一份基于DeepWalk的延伸工作,它改进了DeepWalk随机游走的策略。
Method
Node2Vec认为,现有的方法无法很好的保留网络的结构信息,例如下图所示,有一些点之间的连接非常紧密(比如u, s1, s2, s3, s4),他们之间就组成了一个社区(community)。网络中可能存在着各种各样的社区,而有的结点在社区中可能又扮演着相似的角色(比如u与s6)。
Node2Vec的优化目标为以下两个:
- 让同一个社区内的结点表示能够相互接近,或
- 在不同社区内扮演相似角色的结点表示也要相互接近。
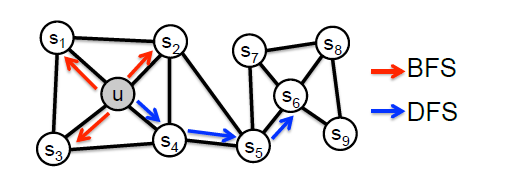
为此,Node2Vec就要在DeepWalk现有的基础上,对随机游走的策略进行优化。Node2Vec提出了两种游走策略:
- 广度优先策略
- 深度优先策略
就如上图的标注所示,深度优先游走策略将会限制游走序列中出现重复的结点,防止游走掉头,促进游走向更远的地方进行。而广度优先游走策略相反将会促进游走不断的回头,去访问上一步结点的其他邻居结点。
这样一来,当使用广度优先策略时,游走将会在一个社区内长时间停留,使得一个社区内的结点互相成为context,这也就达到了第一条优化目标。相反,当使用深度优先的策略的时候,游走很难在同一个社区内停留,也就达到了第二条优化目标。
那么如何达到这样的两种随机游走策略呢,这里需要用到两个超参数p和q用来控制深度优先策略和广度优先策略的比重,如下图所示。
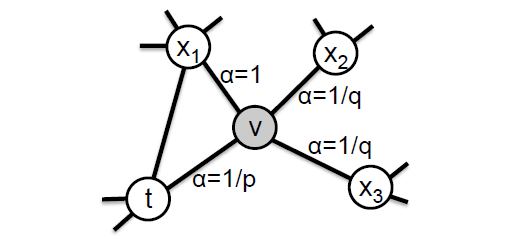
假设现在游走序列从t走到v,这时候需要算出三个系数,分别作为控制下一步走向方向的偏置α
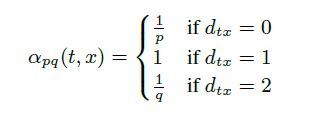
其中d(t, x)代表t结点到下一步结点x的最短路,最多为2。
- 当d(t, x)=0时,表示下一步游走是回到上一步的结点;
- 当d(t, x)=1时,表示下一步游走跳向t的另外一个邻居结点;
当d(t, x)=2时,表示下一步游走向更远的结点移动。
而Node2Vec同时还考虑了边权w的影响,所以最终的偏置系数以及游走策略为
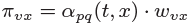
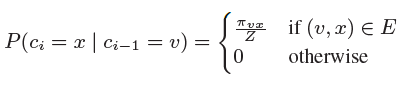
这样一来,就可以看出,超参数p控制的是重新访问原来结点的概率,也就是保守探索系数,而超参数q控制的是游走向更远方向的概率,也就是激进探索系数。如果q较大,那么游走策略则更偏向于广度优先策略,若q较小,则偏向于深度优先策略。
Experiments
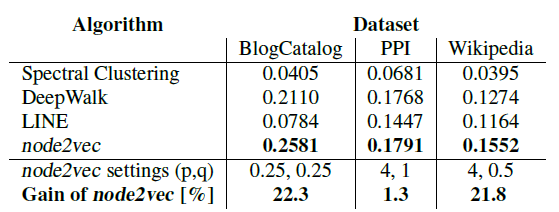
多标签分类任务中可以看出,当调整好适当的p、q值之后,Node2Vec的效果要略好于DeepWalk
四、SDNE: Structural Deep Network Embedding
LINE中提到了一阶相似度以及二阶相似度的概念,那么有没有什么办法,通过深度学习,直接将这两种相似度保留在Embedding中的方法呢?
SDNE提出了这样一个框架,能够使用深度自编码器,在训练的过程中,同时获得节点的一阶相似度和二阶相似度。首先,上面提到了二阶相似度其实是节点邻域的相似程度。换句话说,这样的相似度,其实就直接包含在邻接矩阵S的每一行中。所以SDNE直接使用一个深度自编码器,学习网络邻接矩阵的编码与重构,这样一来,二阶相似度就被保留在了Embedding中,训练相对应的损失函数为
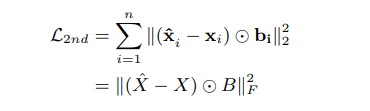
其中x为邻接矩阵的每一行而hat{x}则代表了自编码器重构以后的邻接矩阵。B=1-S,即只针对不直接相邻的节点对进行训练。
接下来就是针对一阶相似度的损失函数了,其实很直接,因为我们最终是将自编码器的隐层当作最终的节点Embedding,所以可以直接像LINE里一样,直接使存在边的两个节点的Embedding相互接近就行了,具体的损失函数如下
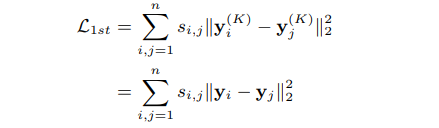
y也就是我们获得的自编码器的隐层。
所以总体的结构如下所示
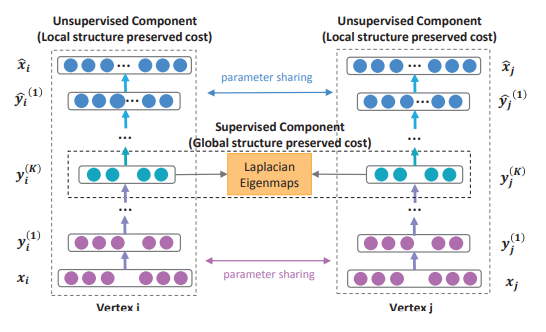
五、HARP: Hierarchical Representation Learning for Networks
上面介绍了DeepWalk、LINE、Node2Vec三个网络表示学习中最为著名的三种算法。但是,这三个算法都有一个共同的弱点,那就是他们所捕捉的网络结点关系过近,都是局部邻居。LINE仅仅只考虑到了一阶邻居与二阶邻居之间的相似度关系。DeepWalk与Node2Vec虽然可以通过随机游走,获得较长的游走序列,但是游走的长度比起现在图数据的规模,随机游走的长度还是太短了。所以就需要想一种方法捕捉全局的相似度。
Method
HARP采取的方式就是通过多次折叠,将原来的大图层层收缩为较小的图,使得通过较短的随机游走距离,就能够覆盖所有的网络结点,然后将小图作为DeepWalk、LINE或Node2Vec的输入,学习Embedding。最后将在收缩后的小图中学习到的Embedding作为折叠前的的图的Embedding的初始化,继续学习折叠前的图的Embedding。以此类推层层学得原来大图的Embedding。HARP的算法流程如下图所示。
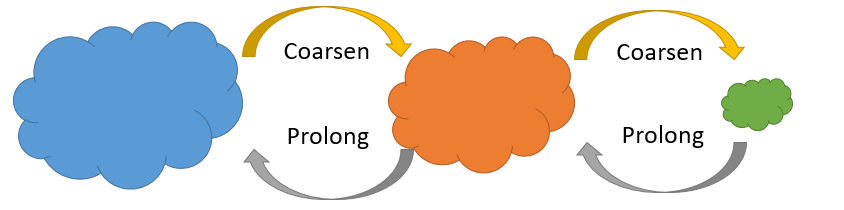
图折叠算法
那么要理解HARP这个算法的关键,就在于图折叠算法。HARP的图折叠算法,主要有以下两种方法
边折叠 (Edge Collapsing)
边折叠算法选择尽可能多的边,这些边没有共同的顶点,即每个顶点只有一条与之连接的边被选中。然后,如下图(a)所示,这些边被折叠成为一个结点,成为了折叠后的新结点。
星折叠 (Star Collapsing)
虽然边折叠在最好的情况下每一轮折叠可以将结点的数量缩减一半,这样一来图折叠算法的总次数为O(logk)。但在某些特殊情况下却不能很好的发挥作用。如下图(b)所示,星形结构是网络中最常见结构之一,在这种结构中,如果使用边折叠算法,那么就至多只能折叠一条边,算法要执行的总次数则会退化为O(k)。所以,HARP采用了另外一种折叠策略,就是星折叠。如下图(c)所示,星状网络中有两种结点,中心结点和周围节点,星折叠方法就是将同一个中心结点的周围结点两两配对,折叠成一个结点,来尽量减少星状结构的周围结点,以增强边折叠的效率。

HARP在每次折叠的时候,先是使用星折叠减少星形结构,然后再执行一次边折叠。具体的图折叠算法流程如下面的伪代码所示。

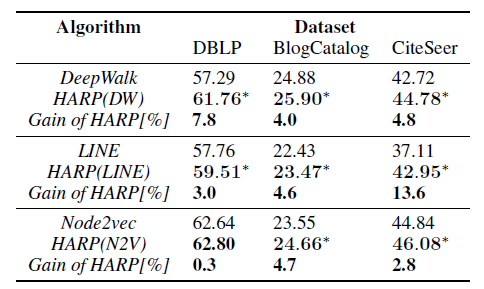
Experiment
通过HARP的多标签分类结果可以看出,使用HARP的图折叠和层级训练的手段后,相较于其相应的底层算法,都有一定的提升。实际上,经过我本人的实验,在更大规模的图上(结点数量达到数十万甚至上百万时),这样的提升将会更加明显。
六、GraphGAN: Graph Representation Learning with Generative Adversarial Nets
GraphGAN这份工作,顾名思义,就是尝试使用生成对抗网络(Generative Adversarial Nets, GAN)来增强网络表示学习的表现。
Method
要是理解GAN,那么GraphGAN的大题模块及其作用应该就能够很容易地想到。GraphGAN一共包含两个主要的模块:
判别器
由于Network Embedding任务大多是无监督,结点本身不带有任何标签,所以判别器要判别的就是网络自身带有的信息,也就是连接信息。GraphGAN中的判别器实际上就是一个连接预测器,通过输入两个结点的Embedding来判定两个结点之间是否存在一条边。
生成器
生成器的作用就是通过合理的方式生成一些点对,然后将这些点对输入到判别器中,尽量让判别器将这两个点对误认为是在图上存在边的两个结点的Embedding。
之后的训练过程就是生成器与判别器较量的过程。生成器不断调整每个结点的Embedding以及自己的参数,使得按照自己的规则生成出来的两个就节点对能够被判别器判别成为存在连接。而判别器则通过调整自身的参数,使自己能够准确的将图中实际存在边的结点对判定为true而将生成器生成的结点对判定为false。他们两个共同组成GraphGAN的目标函数:
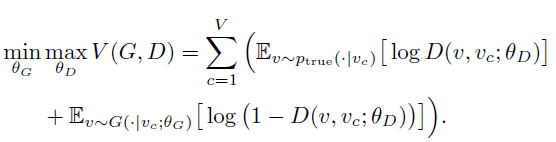
Implemention
那么GraphGAN中的判别器与生成器具体是怎么实现的呢?
前面介绍的DeepWalk、LINE、Node2Vec等方法都是先获得一些context,然后通过训练使得这些结点的Embedding相互接近,然后通过随机的负采样得到一些负样本,让这些负样本的结点之间的Embedding相互远离。事实上GraphGAN的判别器与前面工作的context训练非常相似,也是让ground truth的Embedding相互接近,让生成器生成的节点对的Embedding相互远离。
这样一来生成器看似是代替了原来负采样的过程,然而生成器却需要能够生成与ground truth尽量相似的数据,这就与原来的负采样不太一致。那么这是为什么呢?
产生这样疑惑的原因是我们从以判别器为主的角度来看待这个模型。如果我们从生成器的角度来理解这个模型的时候,这些疑惑就会得到解释。判别器仅仅只是作为训练时的目标函数的实现,它起到的作用有两个,一是让ground truth相互接近,另外一个就是给生成器提供损失函数。而一个经过精心设计的生成器,就可以利用这样的损失函数,训练出我们需要的Embedding。
下面就来介绍一下GraphGAN的生成器是如何工作的。
首先,生成器要遵守以下三个原则:
- Normalized,即所有结点被当作负样本的概率之和为1;
- Graph-structure-aware,结点被选中负样本的概率随着据中心结点的最短路增大而减小;
- Computational efficient,不能针对所有结点来计算softmax,只能关联到一个结点的小子集。
算法开始前,需要生成每个结点的BFS树,然后为了选取某一个结点的负采样,需要沿着该结点的BFS树向下或向上遍历。从某个父节点转移到它的子节点或父节点的概率为:
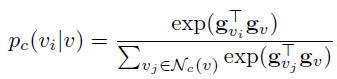
然后,一个结点最终被选取为起始结点的负样本的概率为:
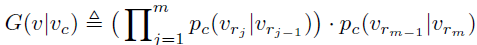
以下图为例子,给定一个图,现在要从vc这个点开始负采样,那么先以vc为根生成BFS树。然后再算出每个结点与其子结点的转移概率,通过这个概率采样子节点,直到哪个结点被遍历了两次,结束。输出这个重复遍历的结点作为负样本。这个遍历过程中涉及到的所有其他结点(绿色结点)都要在训练中训练到。
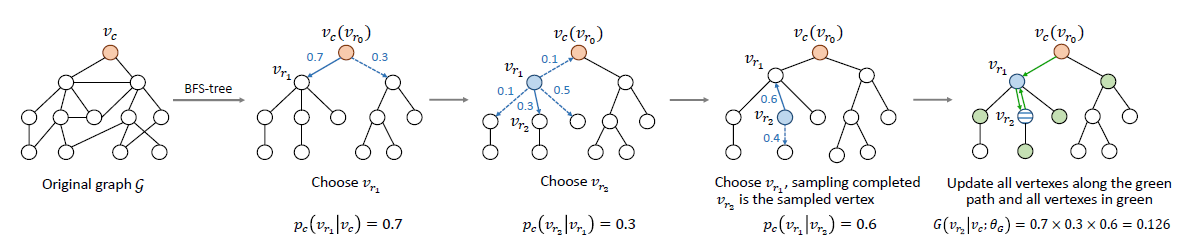
这样的作法复合上面提出的三种原则,论文中给出了详细的证明。
Experiment
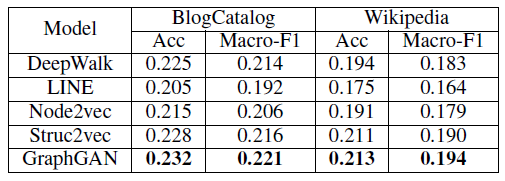
同样来看看GraphGAN的多标签分类的实验结果
七、总结
本文介绍了几种针对网络结构进行表示学习的方法,首先是DeepWalk、LINE、Node2Vec三个最为著名的工作。之后介绍了近两年的一些针对网络结构的网络表示方法HARP和GraphGAN,了解近些年针对结构的网络表示学习的一些新思路。但是,现实中的网络中的内容远远不止结构这么简单。网络中的结点可能有不同的类别,每种结点又可能有不同的属性。所以,还需要有针对利用网络中其他信息的相关研究。
八、参考文献
[1] Perozzi B, Al-Rfou R, Skiena S. Deepwalk: Online learning of social representations[C]//Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014: 701-710.
[2] Tang J, Qu M, Wang M, et al. Line: Large-scale information network embedding[C]//Proceedings of the 24th international conference on world wide web. International World Wide Web Conferences Steering Committee, 2015: 1067-1077.
[3] Grover A, Leskovec J. node2vec: Scalable feature learning for networks[C]//Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2016: 855-864.
[4] Wang D, Cui P, Zhu W, et al. Structural Deep Network Embedding[C]. knowledge discovery and data mining, 2016: 1225-1234.
[5] Chen H, Perozzi B, Hu Y, et al. Harp: Hierarchical representation learning for networks[C]//Thirty-Second AAAI Conference on Artificial Intelligence. 2018.
[6] Wang H, Wang J, Wang J, et al. Graphgan: Graph representation learning with generative adversarial nets[C]//Thirty-Second AAAI Conference on Artificial Intelligence. 2018.